[Coursera] 6. Opitmization
🥑 Coursera의 "Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and
Optimization" 강좌의 내용을 배우면서 개인적으로 정리한 내용입니다.
우리가 일반적으로 사용하는 Gradient Descent은 각 Steop에 모든 Sample m에 대해서 Gradient Steps을 진행한다. 이런 Gradient Descent를 Batch Gradient Descent라고 부른다.
Parameters Update Rule
- for l = 1, ..., L
- W[l] = W[l] − αdW[l]
- b[l] = b[l] − αdb[l]
L은 Layer의 수, α(lpha)는 Learning Rate이다.
다른 Gradient Descent로는 Stochastic Gradient Descent(SGD)가 있다.
확률적 경사하강법이라고 부르며 mini-batch에서의 크기가 1 example인 것과 동일하고 update rule은 동일하나 1개의 example에서 바로바로 gradient를 구해서 계산하는것이 틀리다.

SGD는 진동하면서 수렴하게되는데 데이터가 training set의 크기가 작을 경우 일반 GD가 빠르지만 크기가 큰 경우는 SGD가 빠르다.
Mini-Batch Gradient Descent를 사용하면 더 빠르게 결과를 얻을 수 있다.
- GD 사용 시 전체 training set을 사용하지 않거나 1개의 training example을 사용하지 않고 mini-batch 사용.
- mini-batch는 1~m 사이의 크기로 GD의 각 스텝을 진행.
Mini-Batch Gradient Descent를 어떻게 구현하는지 살펴보자.
다음 2단계를 통해 구현된다.
1. Shuffle
- training set (X,Y)을 섞어준다.
- X,Y를 동일하게 섞어야한다.(X,Y가 다르게 섞이면 안됨!)
- 이 작업은 training example들이 다른 mini-batches로 무작위로 분리되도록 해주는 역할

2. Partition
- 섞인 (X,Y)를 mini-batch-size(32, 64 등등)로 분리해준다.
- 항상 training examples의 수가 mini-batch-size로 나누어 떨어지지 않기 때문에, 마지막 mini-batch의 크기는 mini-batch-size보다 작을 수 있으나 문제되지 않는다.

Momentum
mini-batch GD는 training example의 일부만으로 파라미터를 업데이트 하기 때문에, 업데이트의 변동이 꽤 있으며, 진동하면서 수렴하게 된다.
Momentum을 통해 진동을 감소 시킬 수 있다.
이전의 gradient를 사용하여 진동을 부드럽게 한다. (이전 gradient의 방향 변수 v(경사를 움직이는 속도)에 저장해서 사용한다.)
변수 v는 0으로 초기화하고 grads 딕셔너리와 같은 차원을 가진다.
파라미터 업데이트는 다음과 같은 식을 따른다. (l = 1, ..., L)
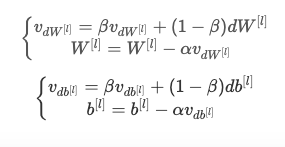
Adam
Adam은 NN을 핛브하는데 가장 효과적인 최적화 알고리즘 중 하나이다.
RMSProp와 Momentum을 결합해서 사용한다.
Adam의 동작 순서
- 모델의 초기 매개 변수를 설정한다.
- 학습률(learning rate), 일반적으로는 작은 양수 값으로 설정한다.
- 모멘트(momentum)와 RMSProp의 개념을 결합하여 매개 변수의 업데이트를 수행한다.
- 매 반복(iteration)마다 다음과 같은 과정을 수행한다:
- 현재 미니배치(mini-batch)의 기울기(gradient)를 계산한다.
- 일정 비율의 모멘트를 사용하여 이전 그래디언트의 이동 평균을 업데이트한다.
- 일정 비율의 RMSProp을 사용하여 이전 그래디언트의 제곱값의 이동 평균을 업데이트한다.
- 편향 보정(bias correction)을 수행하여 모멘트와 RMSProp의 편향 보정 값을 계산한다.
- 계산된 편향 보정 값을 사용하여 매개 변수를 업데이트한다.
- 지정된 반복 횟수나 다른 종료 조건이 충족될 때까지 4단계를 반복한다.
Update Rule은 다음과 같다.
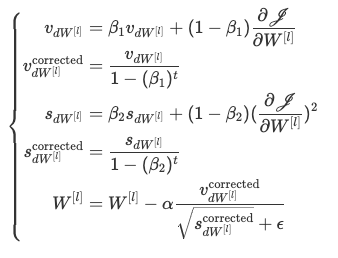
코드 구현(FP, BP, batch,momentum,Optimizer)
Optimization.ipynb
Colaboratory notebook
colab.research.google.com