728x90
반응형
'물꼬기'에서 근무하던 Pupbani는 같은 계열사인 '와인판다'로 파견을 가게 되었다.
와인판다에서는 신제품으로 캔와인을 만들어서 팔기로 했는데 너무 급하게 만들다보니 레드, 화이트 와인 표시가 누락되었습니다.
신팀장은 Pupbani를 불러 다음과 같이 말했습니다.
- "캔에 인쇄된 알코올 도수, 당도, pH 값으로 와인 종류를 구별하는 머신러닝 프로그램을 만들어주세요."
- "품질 확인용으로 뜯은 캔들도 있기 때문에 데이터는 충분할겁니다."
Pupbani는 로지스틱 회귀 모델을 적용해보기로 했다.
데이터 준비
- pandas 라이브러리를 통해 데이터를 불러왔다.
- 데이터가 누락된 값이 있는지 확인해보자 - info() 메서드
- 데이터 열에 대한 간단한 통계를 알아보자 - describe() 메서드
- mean : 평균
- std : 표준편자
- min : 최소
- 25% : 1사분위수
- 50% : 중간값 / 2사분위수
- 75% : 3사분위 수
- max : 최대
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine-date')
wine.info()
wine.describe()

- 누락값도 없고 데이터가 잘 들어있다.
- 데이터를 특성값들과 타깃값으로 나누고 이 데이터로 훈련 세트와 테스트 세트를 만든다.
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42)- 표준 점수화를 한다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)모델 학습과 평가
- 로지스틱 회귀 모델을 통해 학습을 하고 모델 평가를 진행 한다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(f'훈련세트 정확도: {lr.score(train_scaled, train_target)*100:.2f}%')
print(f'테스트 세트 정확도: {lr.score(test_scaled, test_target)*100:.2f}%')
- 과소적합된 것 같다.
- 모델의 계수와 절편을 출력해서 보고서를 만들어서 신팀장에게 제출해보자.
print(f"계수 : {lr.coef_[0]}")
print(f"절편 : {lr.intercept_}")

보고서를 제출하자 신팀장은 다음과 같이 말했다.
- "너무 복잡해서 이해 못하겠어요."

- "순서도 처럼 쉽게 설명해서 다시 가져오세요."
결정 트리(Decision Tree)
- 손 선배는 결정 트리 모델이 "이유를 설명하기 쉽다."라고 알려 주었다.
- 결정 트리는 스무고개와 같다.
- 질문을 하나씩 던져서 정답을 맞춰간다.
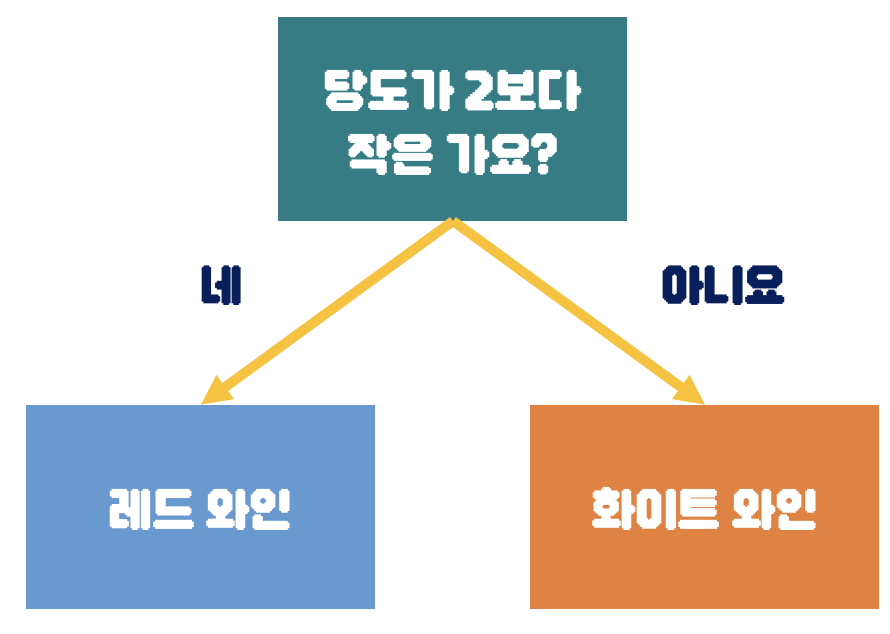
- 사이킷런의 DecisionTreeClassifier 클래스를 사용하면 결정 트리를 구현할 수 있다.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(f'훈련 세트 정확도: {dt.score(train_scaled, train_target)*100:.2f}%')
print(f'테스트 세트 정확도: {dt.score(test_scaled, test_target)*100:.2f}%')
- 훈련 세트가 테스트 세트에 비해 엄청 높다 - 과대적합 모델
- 트리를 시각화 해보자
- 사이킷런은 plot_tree() 함수를 사용해 결정 트리를 이해하기 쉬운 그림으로 출력해 준다.
- 트리에서 제일 위에 달린 노드를 루트(root) 노드라고 한다.
- 트리에서 제일 아래 달린 노드를 리프(leaf) 노드라고 한다.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()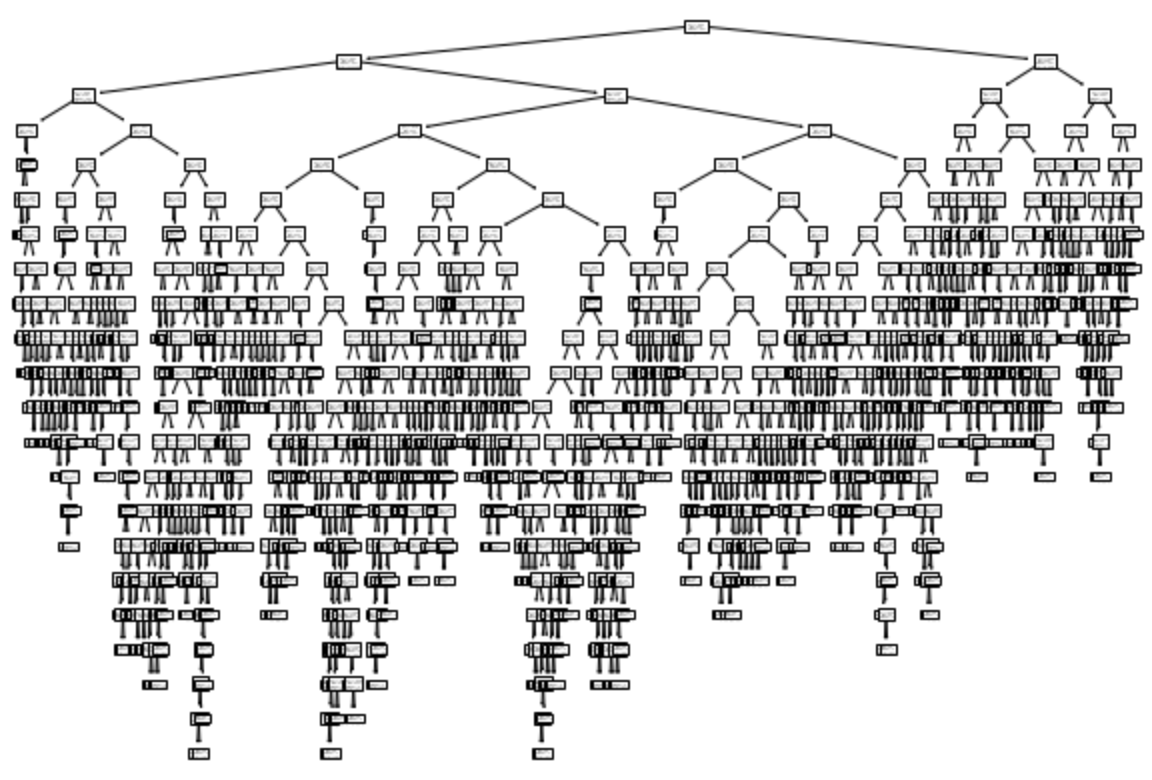
- 너무 복잡하니 트리의 깊이를 제안해서 일부만 확인해 보기로 한다.
- max_depth 매개변수를 1로 주면 루트 노드를 제외하고 하나의 노드를 더 확장하여 그린다.
- filled 매개변수로 클래스에 맞게 노드를 색을 칠할 수 있다. - 비율이 높아지면 점점 더 진한 색으로 칠한다.
- feature_names 매개변수에는 특성의 이름을 전달할 수 있다.
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()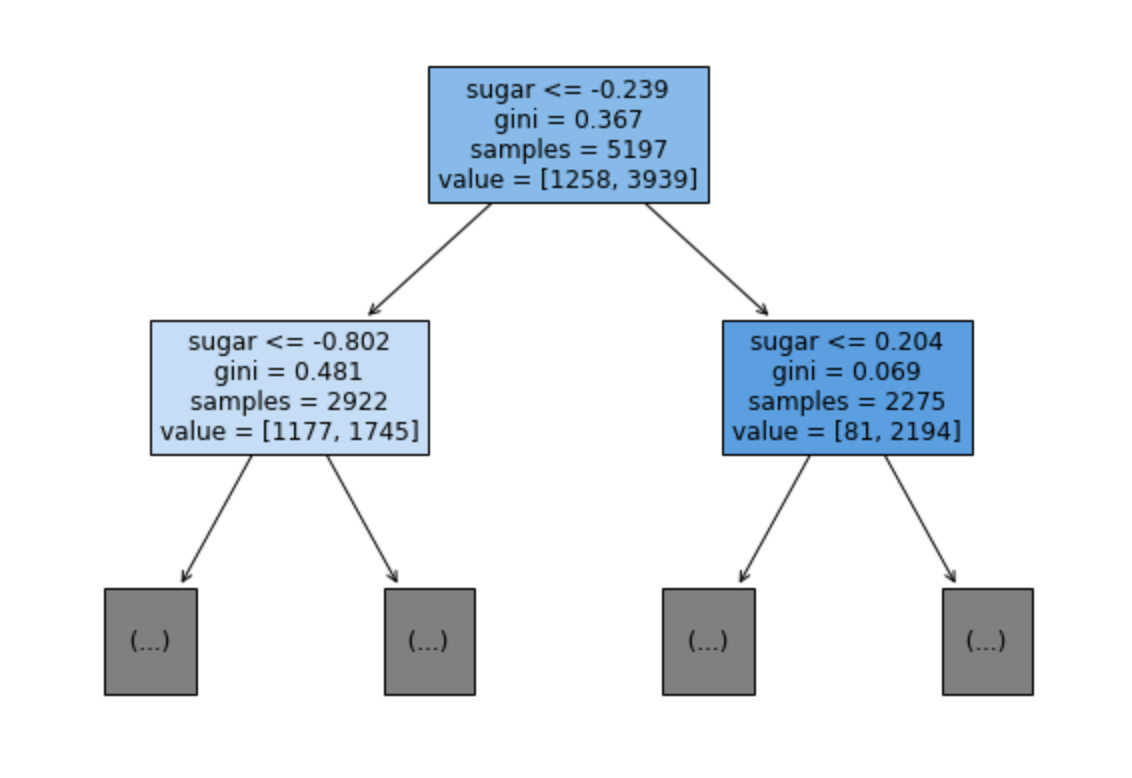
- 이제 좀 보기 좋게 나왔다.
- 그림을 읽는 법을 알아보자
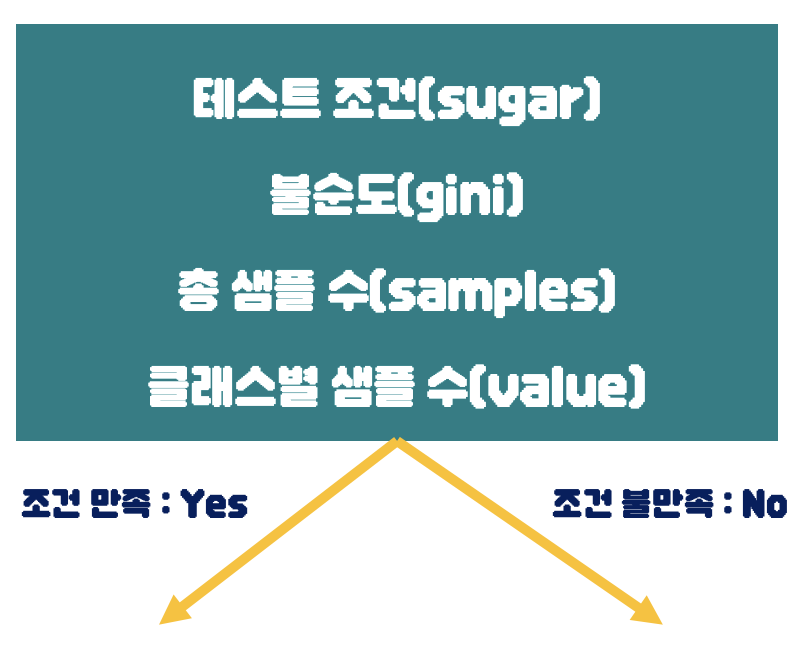
- 노드의 내용은 위의 그림과 같다.
- 실제 값으로 분석을 한번 해보자.

- 만약 어떤 샘플의 당도가 -0.239 이하이면 왼쪽, 크다면 오른쪽 노드로 이동
- 지니 불순도(Gini Impurity) : 0.367 = 1 - ((1258 / 5197)^2 + (3939 / 5197)^2)
- 총 샘플의 개수 : 5197개
- 음성 클래스(레드 와인) : 1258개
- 양성 클래스(화이트 와인) : 3939개
지니 불순도(Gini Impurity)
- DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값이 'gini'이다.
- 노드에서 데이터를 분할할 기준을 정하는 것 이다.

- 순수 노드 : 지니 불순도가 0인 노드, 노드에 하나의 클래스만 있는 노드
- 결정 트리는 부모 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장 시킨다.
- 부모와 자식 노드의 불순도의 차이를 계산하는 방법을 알아보자

- 이렇게 얻어진 부모와 자식 노드 간의 불순도 차이를 정보 이득(Information gain)이라고 부른다.
- 또 다른 불순도 기준이 있다.
엔트로피 불순도
- DecisionTreeClassifier 클래스의 criterion = "entropy"로 지정하면 엔트로피 불순도를 사용한다.
- 엔트로피 불순도도 노드의 클래스 비율을 사용하나 밑이 2인 로그를 사용하여 곱한다.

결정 트리 알고리즘은 불순도 기준을 사용해 정보 이득이 최대가 되도록 노드를 분할 한다.
노드를 순수하게 나눌수록 정보 이득이 커진다.
새로운 샘플에 대해 예측 시 노드의 질문을 따라 트리를 이동하여 마지막에 도달한 클래스 비율을 보고 예측을 만든다.
그런데 앞의 트리는 제한 없이 자라났기 때문에 과대적합이 일어났다.
과대적합을 해결하려면 어떻게 해야할까?
가지치기
- 결정 트리는 가지치기를 통해 일반화를 한다.
- 훈련 세트와 테스트 세트의 점수가 비슷하다.
- 가지치기를 하는 방법은 자라날 수 있는 트리의 깊이를 제한하는 것이다.
- DecisionTreeClassifier 클래스의 max_depth 매개변수를 수정하여 깊이를 제한할 수 있다.
- 이제 모델을 학습 시켜보자.
- 결정 트리는 특성값의 스케일에 영향을 받지 않기 때문에 표준 점수화를 하지 않아도 된다.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target)
print(f'훈련 세트 정확도: {dt.score(train_input, train_target)*100:.2f}%')
print(f'테스트 세트 정확도: {dt.score(test_input, test_target)*100:.2f}%')
- 훈련 세트의 성능은 낮아졌지만 테스트 세트의 성능은 거의 그대로 이다.
- 전체적인 성능은 낮으나 두 세트의 점수가 비슷하므로 일반화되었다고 할 수 있다.
- 학습한 모델로 트리를 그려보자
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()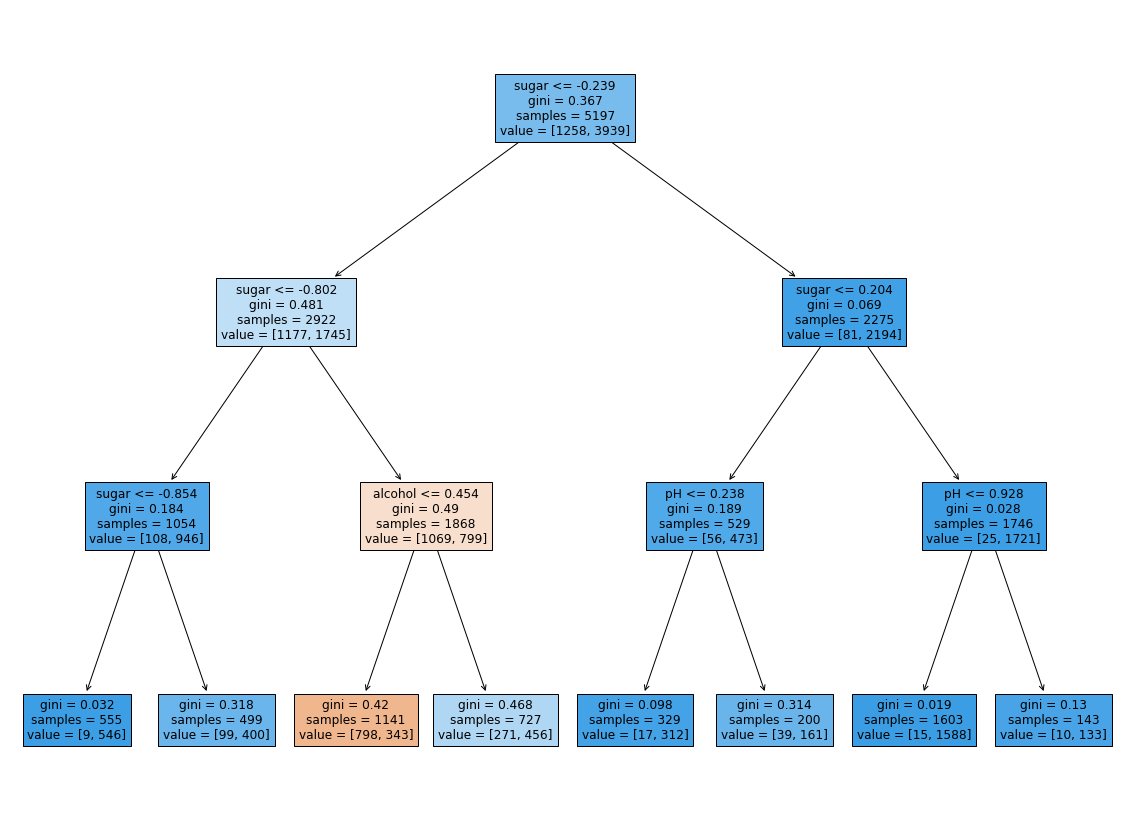
- 결정 트리는 어떤 특성이 가장 유용한지 나타내는 특성 중요도를 계산해준다.
- 이 특성 중요도는 feature_importances_ 속성에 저장되어 있다.
fimpt = dt.feature_importances_.reshape(-1,3).round(4) * 100
feature = list(wine.columns)[0:3]
print(pd.DataFrame(fimpt,columns=feature))
- 이 모델에서는 sugar가 가장 유용한 특성이다.
성능이 많이 높지 않아 화이트 와인을 완벽하게 골라내지는 못하지만 보고하기엔 좋은 모델인 것 같다.
모델에 대해 보고하러 가보자.
728x90
반응형
'AI > 기계학습(Machine Learning)' 카테고리의 다른 글
| [기계학습/ML]12. 앙상블 학습 - 랜덤 포레스트, 엑스트라 트리, 그레이디언트 부스팅 (0) | 2022.10.24 |
|---|---|
| [기계학습/ML]11. 검증 세트 - 교차 검증, 그리드 서치 (0) | 2022.10.24 |
| [기계학습/ML]9. 확률적 경사 하강법 - 손실 함수, 에포크 (0) | 2022.10.23 |
| [기계학습/ML]8. 회귀 알고리즘(3) - 로지스틱 회귀 (0) | 2022.10.23 |
| [기계학습/ML]7. 회귀 알고리즘(2) - 다중 회귀, 릿지(Ridge), 라쏘(Lasso) (0) | 2022.10.23 |



