마케팅 팀장이 Pupbani를 불렀습니다. 무슨 일일까??
이번에 회사에 새로운 분야 진출을 한다고 한다.
그 분야는 바로 패션 분야로 럭키백 이벤트를 진행 예정이라고 한다.
그래서 마케팅 팀장은 Pupbani에게 럭키백에 들어갈 옷들의 정확도를 높여 달라고 부탁했다.
패션 MNIST 데이터
먼저 데이터를 불러와 보겠다.
옷의 데이터는 텐서플로(TensorFlow)라는 라이브러리를 통해 불러올 수 있다.
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print("훈련 세트 -->",train_input.shape, train_target.shape)
print("테스트 세트 -->",test_input.shape, test_target.shape)
훈련 세트의 입력 데이터는 28 x 28 이미지가 총 60,000개, 타겟 데이터는 60,000개가 있고
테스트 세트의 입력 데이터는 28 x 28 이미지가 총 10,000개, 타겟 데이터는 10,000개 있다.
이렇게 불러온 데이터를 몇개만 시각화 해보겠다.
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
이 MNIST 데이터의 타겟은 0~9까지의 숫자 레이블로 구성된다.
| 레이블 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 패션 아이템 | 티셔츠 | 바지 | 스웨터 | 드레스 | 코드 | 샌달 | 셔츠 | 스니커즈 | 가방 | 앵클 부츠 |
넘파이 unique()로 레이블당 샘플개수를 확인해 보자.
import numpy as np
label = {0:"티셔츠",1:"바지",2:"스웨터",3:"드레스",4:"코드",5:"샌달",6:"셔츠",7:"스니커즈",8:"가방",9:"앵클 부츠"}
data = np.unique(train_target, return_counts=True)
for l,c in zip(data[0],data[1]):
print(label[l],f": {c}개")

로지스틱 회귀로 패션 아이템 분류하기
이제 분류 모델을 학습 해보자.
훈련 데이터의 크기가 60,000개로 엄청 많기 때문에 샘플을 나눠서 학습하는 확률적 경사하강법을 사용해서 학습해보자.
SGDClassifier를 사용한다.
SGDClassifier는 특성 중 기울기가 가장 가파른 방향을 따라 이동하는데 특성마다 값을 범위가 많이 다르면 올바르게 손실 함수의 경사를 내려 올 수 없다.
MNIST의 경우 0~255 사이의 정숫값을 가지므로 0~1 사이로 정규화를 한다.
train_scaled = train_input / 255.0먼저 데이터의 형태를 1차원 배열로 만든다.
train_scaled = train_scaled.reshape(-1, 28*28)
print(train_scaled.shape)
SGDClassifier 클래스와 cross_validate 함수를 사용해 이 데이터에서 교차 검증으로 성능을 확해보자.
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
# 손실함수: 로지스틱 회귀, 반복횟수 5번
sc = SGDClassifier(loss='log', max_iter=5, random_state=42)
# 병렬 수행할 CPU 코어 전체 사용
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
# 교차 검증의 최종 점수는 test_score 키에 담긴 점수의 평균
print(np.mean(scores['test_score']))
최종 점수가 0.81956가 나왔다.
만족할 정도의 점수는 아니다.
로지스틱 회귀의 분류 값을 구하는 공식을 MNIST 데이터에 적용해보자.

위의 공식과 같은 형태로 작성할 수 있다.
공식을 그림으로 나타내면 다음과 같다.

각 클래스를 계산하기 위한 784개의 픽셀과 곱한 가중치 784개와 절편 b는 클래스 마다 다른 값을 가진다.
이 선형 방정식을 계산한 후 소프트맥스 함수를 통과하여 각 클래스에 대한 확률을 얻을 수 있다.
인공 신경망
인공 신경망은 머신러닝 기법을 한 분야로 인공 뉴런을 사용하여 예측이나 분류를 수행하는 알고리즘이다.
인공 신경망은 1943년 워런 매컬러(Warren McCulloch)와 윌터 파츠(Walter Pitts)가 제안한 뉴런 모델에서 시작 되었다.

이 모델은 실제 생물학적 뉴런에서 영감을 받았다.

가장 기본적인 인공 신경망은 확률적 경사 하강법을 사용하는 로지스틱 회귀와 같다.
다음 그림은 인공 신경망을 그림으로 나타낸 것이다.
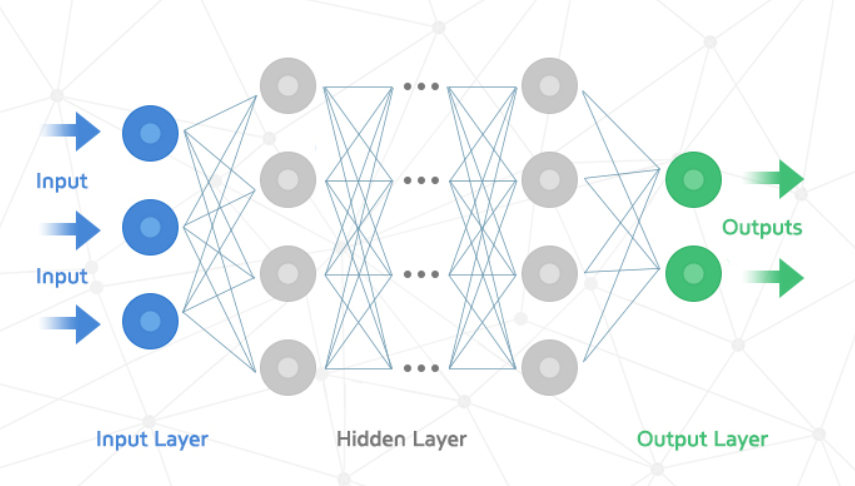
인공 신경망에서 z값을 계산하는 단위 그림에서 보면 동그라미에 해당하는 부분을 뉴런(Neuron) 또는 유닛(Unit)이라고 부른다.
인공 신경망은 크게 다음과 같이 3가지의 층으로 나눌 수 있다.
- 입력층
- 아무런 계산을 하지 않는 층이다.
- 입력 데이터에 해당하는 층이다.
- 데이터를 한 줄로 펼친 1차원 배열의 형태이다.
- 은닉층
- 입력층과 출력층 사이에 있는 층으로 여러 개가 존재할 수도 있다.
- 입력층의 데이터를 가지고 계산을 수행한다.
- 출력층의 바로 전 은닉층은 반드시 출력 개수가 출력층의 입력 개수와 같아야 한다.
- 출력층
- 최종적으로 나오는 값들이 있는 층이다.
- 출력층의 값을 바탕으로 클래스를 예측한다.
인공신경망 모델로 분류하기
인공신경망 모델을 사용하려면 텐서플로(TensorFlow)라는 딥러닝 라이브러리를 사용해야한다.
import tensorflow as tf텐서플로는 케라스(Keras)라는 고수준 API를 사용하여 인공신경망을 훈련한다.
이 케라스는 직접 GPU 연산을 수행하지 않고 대신 연산을 해주는 라이브러리를 백엔드로 사용한다.텐서플로가 케라스의 백엔드 중 하나다.
from tensorflow import keras이제 모델을 만들어보자.
이전에 사용한 train_scaled 데이터와 train_target 데이터를 사용한다.
20%를 검증 세트로 덜어내고 나머지는 훈련 세트로 사용한다.
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
print("훈련 세트 크기 :",train_scaled.shape, train_target.shape)
print("검증 세트 크기 :",val_scaled.shape, val_target.shape)
케라스의 레이어 패키지(keras.layers)를 사용하여 기본이 되는 층인 밀집층(Dense Layer)를 만들어보자.
- 왼쪽의 입력 데이터와 오른쪽 출력 뉴런이 모두 층과 연결되어 있다.
- 이렇게 연결된 선을 계산해보자면 784 x 10 = 7,840개다.
- 빽빽하게 연결되어 있어 밀집층이라고 하고 완전 연결층(Fully Connected Layer)라고도 한다.
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
model = keras.Sequential(dense)Dense 클래스의 매개변수는 다음과 같다.
- 출력 될 뉴런 개수
- 뉴련의 출력에 적용할 함수 == 활성화 함수(Activation Function)
- softmax , sigmoid, relu,...
- input_shape : 입력 형태
Sequential 클래스에 dense 객체를 전달해 층이 형성된 모델 객체를 반환한다.
이제 모델의 훈련 설정을 해줘야한다.
이러한 설정을 하는 메서드는 complie()이다.
- 손실 함수 지정
- 훈련 과정에서 측정하고 싶은 측정값
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')loss는 손실함수를 지정한다.
- 이진 분류 : binary_crossentropy
- 다중 분류 : categorical_crossentropy
- sparse_를 앞에 붙히면 원핫 인코딩을 하지 않은 타겟 값을 사용가능함.
원핫 인코딩(One-hot encoding)
- 타겟값을 해당 클래스는 1 나머지는 0인 배열로 만드는 것.
- 다중 분류에서 크로스엔트로피 손실 함수를 사용하기 위해 필요함.
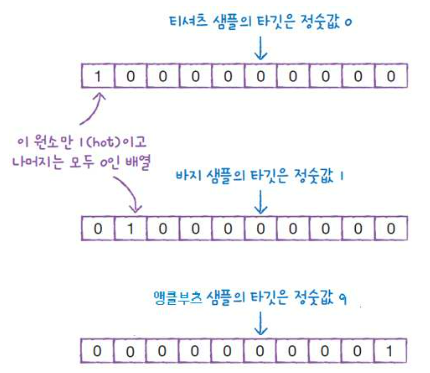
metrics는 측정값을 지정한다.
- accuracy : 정확도 지표
이제 모델 훈련을 해보자.
모델을 훈련은 fit() 메서드를 사용해서 할 수 있다.
epochs 매개변수를 지정하여 에포크 횟수를 정할 수 있다.
batch_size라는 매개변수도 있는데 기본값으로 32를 가진다.
model.fit(train_scaled, train_target, epochs=5)
정확도는 최종 적으로 0.8550가 나왔다.
Epoch 밑에 1500/1500 숫자는 입력 데이터 총 개수 / batch_size == 48000 / 32를 한 것이다.
훈련이 완료된 모델의 성능을 확인해보자.
성능 확인은 evaluate() 메서드를 사용해 할 수 있다.
model.evaluate(val_scaled, val_target)
검증 점수는 약 0.8539 정도가 나왔다.
Pupbani는 딥러닝 사용해 패션아이템을 분류하는 모델을 만들었다.
'AI > 딥러닝(Deep Learning)' 카테고리의 다른 글
| [딥러닝/DL]6. 합성곱 신경망의 시각화 (0) | 2022.12.08 |
|---|---|
| [딥러닝/DL]5. 합성곱 신경망을 사용한 이미지 분류 (1) | 2022.12.08 |
| [딥러닝/DL]4. 합성곱 신경망 - 구성요소 (0) | 2022.12.07 |
| [딥러닝/DL]3. 신경망 모델 훈련 (0) | 2022.12.07 |
| [딥러닝/DL]2. 심층 신경망 (0) | 2022.12.07 |



