🥑 Coursera의 "Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and
Optimization" 강좌의 내용을 배우면서 개인적으로 정리한 내용입니다.
Train/Dev/Test
처음 딥러닝 모델을 구현할 때 한번에 적절한 하이퍼 파라미터 값을 찾는 것은 거의 불가능하다.
그래서 반복적인 과정을 통해 값을 수정하며 적절한 하이퍼 파라미터 값을 찾아야한다.

이 반복 과정에서 가장 중요한것은 반복 과정을 얼마나 효율적으로 하느냐이다.
우리는 Data를 Train/Dev/Test Set 총 3개의 그룹으로 분리하고 적절히 설정하면 효율적으로 수행할 수 있다.
Training Set
- 학습 알고리즘을 계속 수행한다.
Dev or CV Set
- 다른 많은 모델 중에 어떠한 모델이 가장 성능이 좋은지 평가한다.
- Test Set과 같은 분포도를 가지는 것이 좋다.
Test Set
- Dev or CV Set을 통해 가장 적절한 모델을 찾으면 최종적으로 모델을 평가한다.
- bias가 없는 결과값이 목표이므로 사용된다.
- bias가 중요하지 않다면 사용하지 않아도 된다.
일반적으로 Training 과 Test로 분리할 경우 70:30 비율로, Dev가 추가되면 60:20:20으로 분리하게 된다.
하지만, 이경우는 데이터의 크기가 작을 경우 합리적인 방법이다.
빅데이터 같은 경우 데이터의 수가 수백만개가 넘어가기 때문에 Dev, Test는 작은 비율을 차지한다.
예를 들어 1,000,000개의 데이터가 있을 경우 Dev와 Test는 10,000개 정도면 충분하다.
Bias/Variance
데이터 분포를 3가지를 비교하며 살펴보자
High Bias 그림은 데이터가 Fitting 되지 않아서 Underfitting의 문제를 가진다.
High Variance 그림은 아주 복잡한 분류기(ex. DNN)에 Fitting 시켰기 때문에 데이터를 완벽하게 Fitting하게되서 Overfitting의 문제를 가진다.
Just Right 그림은 적절하게 Fitting된 모델이다.
이 그림들 처럼 2개의 입력에 대해 Decision Boundary를 그리면 시각적으로 확인이 가능하지만 고차원의 입력을 가지는 경우는 시각적으로 확인 어렵기 때문에 다른 방법이 필요하다.
방법1 : Cross Validation을 활용한 성능 평가
- 데이터를 Train/Val/Test로 나누어 모델을 훈련하고 성능을 평가.
- Underfitting : Train과 Val 모두 성능이 낮게 나옴.
- Overfitting : Train은 높지만 Val의 성능이 낮게 나옴.
방법2 : 학습 곡선(Learning Curve) 분석
- 학습 곡선은 훈련 데이터의 크기에 따른 훈련 세트와 검증 세트의 성능 변화를 나타내므로 이것을 통해 확인.
- Underfitting : Train과 Val 모두에서 성능이 수렴.
- Overfitting : Train은 높지만 Val의 성능이 수렴하지 않음.
방법3 : 복잡도에 따른 성능 비교
- 모델의 복잡도를 조절하여 성능을 비교함.
- Underfitting : 모델이 너무 단순하여 Train의 성능이 매우 낮게 나옴.
- Overfitting : 모델이 너무 복잡하여 Train의 성능이 매우 높게 나옴.
이 정보들을 Basic Recipe라고 한다. 이를 통해 머신러닝의 시스템적인 부분을 알 수 있게 해주고 알고리즘 성능에 기여할 수 있다.
예를 들어 초기 모델 학습 이후 알고리즘이 High Bias문제가 있다면, 더 복잡한 모델을 선택하거나 더 많은 반복 학습, 최적화된 알고리즘 선택을 할 수 있고, High Bias 문제가 없고 High Variance 문제가 있다면, 더 많은 데이터를 수집하거나 정규화(Regularization)을 시도할 수 있다.
Regularization
어느 모델이 Overfitting 하다면 High Variance 문제가 있는 것이고, 정규화를 시도해봐야 한다.
다른 방법으로는 데이터를 더 수집하는 방법이 있지만 데이터 수집은 일반적으로 어렵거나 비용이 많이 들기 때문에 정규화를 이용한다.
가장 일반적인 정규화 방법으로 L1과 L2 규제가 잇다.
L1 Regularization

- 가중치의 절댓값에 비례하는 패널티를 부과하여 모델의 가중치를 규제하는 정규화 방법이다.
- 일부 가중치를 0으로 만들 수 있어 Feature Selection 효과(중요하지 않은 특성 제거)를 가질 수 있다.
- 희소성(Sparsity)을 가지는 모델을 만들 수 있고 적은 수의 중요 특성들만 사용하여 모델을 구성할 수 있다.
- Lasso 규제라고도 한다.
- Manhatten Distance(특정 방향으로만 움직일 수 있는 경우의 두 벡터간의 최단 거리를 찾는 방법)를 사용하여 가중치의 절댓값에 비례하는 패널티를 부과한다.
alpha = 0.1 # 규제의 강도를 조절하는 매개변수
# 기존 비용 함수
cost = ...
# L1 규제를 적용한 비용 함수
l1_regularization = alpha * (abs(w1) + abs(w2) + ... + abs(wn))
cost_with_l1 = cost + l1_regularization
L2 Regularization

- 가중치의 제곱에 비례하는 패널티를 부과하여 모델의 가중치를 규제하는 정규화 방법이다.
- 모든 가중치가 0에 가까워지도록 만들어 전체적으로 가중치를 줄이는 효과가 있다.
- 가중치를 0에 가깝게 만들지만 0이되지 않고 아주 작은 값을 가진다. Feature Selection 효과가 L1보다 작다.
- 이상치에 취약하다.
- Ridge 규제라고도 한다.
- Euclidean Distance(두 점 사이의 최단 거리를 측정할 때 사용)를 사용하여 가중치의 제곱에 비례하는 패널티를 부과한다.
alpha = 0.1 # 규제의 강도를 조절하는 매개변수
# 기존 비용 함수
cost = ...
# L2 규제를 적용한 비용 함수
l2_regularization = alpha * (w1**2 + w2**2 + ... + wn**2)
cost_with_l2 = cost + l2_regularization
Deep Learning에서 이 규제들이 어떻게 Overfitting을 막아주는 것일까?
예를 들어 L1 또는 L2 규제를 강하게 가하게 되면 W값을 0또는 0에 가까운 값으로 만들기 때문에 Hidden Layer의 Unit들의 영향을 0으로 만들기 때문에 신경망을 간단하게 만들 수 있다. (* L2의 경우 0이 아니라 0에 가까운 값이므로 hidden unit의 영향이 줄어든것이고 사용 안하는 것은 아님!)
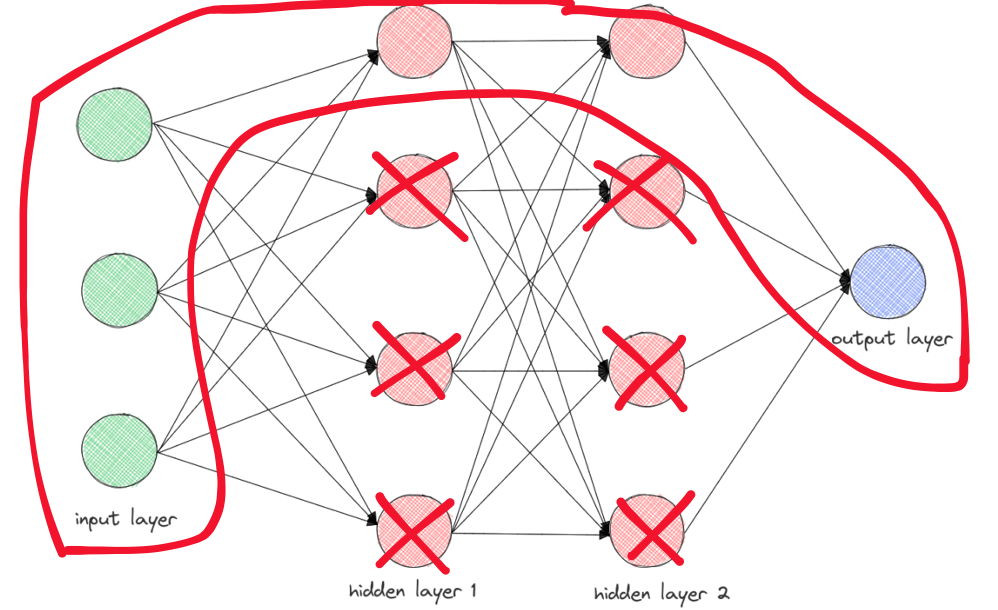
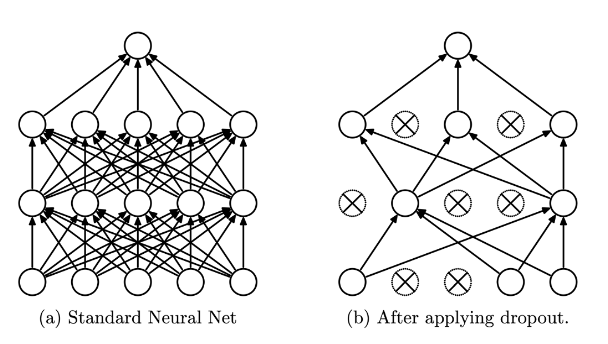
Dropout Regularization
훈련과정에서 신경망의 일부 뉴런을 무작위로 선택하여 제외하는 방식으로 작동한다.(L2 정규화와 비슷하게 동작)
이는 각 뉴런이 훈련 데이터에 독립적으로 기여하는 것을 방지하기 위해 사용된다.
주로 Computer Vision(데이터가 충분하지 않은 경우가 일반적이므로 Overfitting이 거의 항상 일어남)된다.
신경망의 뉴런들에 의존하지 않고 여러 개의 서로 다른 부분집합으로 작동하도록 유도된다.
- 신경망의 일반화 능력 향상시킴.
- 여러가지 특징을 골고루 학습할 수 있게 도와줌.
일반적으로 훈련과정에서만 적용되며 훈련 종료 후에는 드롭아웃을 비활성화하고 모든 뉴런을 사용하여 예측을 수행한다.
하지만, 적절한 비율과 사용방법은 모델과 데이터에 따라 다르므로 적절히 사용해야 한다.
단점
- Cross-validation에서 설정해야할 하이퍼파라미터가 증가한다.
- Cost Function J가 명확하게 정의(반복 마다 노드를 무작위를 제거하기 때문)되지 않는다.
- Gradient Descent 성능을 더블 체크하기 어렵다.
Data augmentation
데이터가 비싸고 수집하기 어려운 경우 사용하는 방법으로, 원본 데이터를 조금씩 수정해서 새로운 데이터를 확보하는 방법이다.
ex. 이미지를 뒤집기, 회전, 찌그러뜨리기, 줌인 등의 방법으로 새로운 데이터 생성
이 방법은 큰 비용 없이 overfitting을 줄이는 방법이다.
Early Stopping
Gradient Descent를 실행하면서 Training Set Error나 Cost function과 Dev set error 그래프를 그려 W가 middle-size일 때 중단시키는 방법이다.
- 학습을 하면 W는 증가하게되는데 W의 비율이 중간 정도되는 지점에 중지한다.
- 검증 데이터의 손실이 일정 기간 동안 감소하지 않거나 증가하기 시작하는 경우 훈련을 조기 종료한다.
훈련 시간과 리소스를 절약할 수 있는 정규화 방법이다. 그러나, 최적화를 완벽하게 하지 못하고 Cost Function을 더이상 줄일 수 없으므로 이후 최적화를 하기 위한 방법들을 더 복잡하게 하는 단점이 있다.
Practical Aspects of Deep Learning.ipynb
Colaboratory notebook
colab.research.google.com
'AI > Coursera' 카테고리의 다른 글
| [Coursera] 6. Opitmization (0) | 2023.12.31 |
|---|---|
| [Coursera] 5. Optimization Problem (0) | 2023.12.28 |
| [Coursera] 3. Gradient Descent (0) | 2023.12.27 |
| [Coursera] 2. Logistic Regression (0) | 2023.12.17 |
| [Coursera] 1. Neural Network (0) | 2023.08.28 |



