728x90
반응형

MLflow는 Machine Learning Lifecycle Platform으로 ML Lifecycle을 관리한다.
오픈소스 플랫폼이며 ML 학습 프로젝트의 전체 수명 주기에 중점을 두어 각 단계를 관리, 추적 및 재현할 수 있도록 보장한다.
주요기능 4가지
- MLflow Tracking : ML을 학습할 때 생기는 각종 Parameters, Training 후 metric의 결과 등을 logging하고 logging 기록을 Web UI로 확인할 수 있다.
- MLflow Projects : Anaconda, docker 등을 사용해서 만들어 둔 모델을 재현하고 실행할 수 있도록 코드 패키지 형식으로 지원, 이 형식으로 만들어진 환경을 재사용할 수 있다.
- MLflow Models : 동일한 모델을 Docker, Apache Spark, AWS 등에서 쉽게 배치할 수 있도록 지원
- MLflow Model Registry : MLflow 모델의 전체 Lifecycle을 공동 관리하기 위한 centralized model store, set of API, UI
MLflow 시작하기
먼저 mlflow를 설치한다.
pip install mlflow
데이터 전처리 및 모델을 트레이닝하는 코드를 작성한다.
- 데이터는 iris 데이터를 사용해 보겠다.
from sklearn import datasets
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
import tensorflow as tf
# Data Load
def dataLoad():
X, y = datasets.load_iris(return_X_y=True, as_frame=True)
return X, y
# model Training
class Iris_Model:
def __init__(self) -> None:
self.scaler = StandardScaler()
# train
self.train_X = self.train_y = None
# valid
self.valid_X = self.valid_y = None
# test
self.test_X = self.test_y = None
# models
self.sk_model = None
self.ks_model = None
def preprocessing(self, X, y, size=0.6) -> None:
# split
self.train_X, X_, self.train_y, y_ = train_test_split(
X, y, train_size=size, random_state=42)
self.valid_X, self.test_X, self.valid_y, self.test_y = train_test_split(
X, y, train_size=0.5, random_state=42)
# data scale
self.train_X = self.scaler.fit_transform(self.train_X)
self.valid_X = self.scaler.transform(self.valid_X)
self.test_X = self.scaler.transform(self.test_X)
def sklearn_model(self, n_estimator: int) -> dict:
X, y = dataLoad()
self.preprocessing(X, y)
self.sk_model = RandomForestClassifier(
n_estimators=n_estimator, max_depth=5)
self.sk_model.fit(self.train_X, self.train_y)
# tpre = self.sk_model.predict(self.train_X)
vpre = self.sk_model.predict(self.valid_X)
model_info = {
'score': {
'model_score': accuracy_score(y_true=self.valid_y, y_pred=vpre)
},
'params':
self.sk_model.get_params()
}
return model_info
def keras_model(self, epoch: int) -> dict:
X, y = dataLoad()
self.preprocessing(X, y)
input_layer = tf.keras.Input(
shape=(self.train_X.shape[1],), name="Inp_Layer")
dense_1 = tf.keras.layers.Dense(
32, activation='relu', name='d1')(input_layer)
dense_2 = tf.keras.layers.Dense(
10, activation='relu', name='d2')(dense_1)
output = tf.keras.layers.Dense(
3, activation='softmax', name='output')(dense_2)
self.ks_model = tf.keras.Model(inputs=input_layer, outputs=output)
self.ks_model.compile(
loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
y = pd.get_dummies(self.train_y).astype('int')
self.ks_model.fit(
self.train_X, y, epochs=epoch, batch_size=10
)
y = pd.get_dummies(self.valid_y).astype('int')
model_info = {
'score': {
'model_score': np.float64(round(self.ks_model.evaluate(self.valid_X, y)[1], 2))
},
'params': {'epochs': epoch, 'batch_size': 10}
}
return model_info
MLflow와 함께 전체 코드를 실행하는 코드를 작성한다.
- 모델 훈련부터 검증 까지는 함수로 구현해줘야함.
from train import Iris_Model, dataLoad
# mlflow
import mlflow
from mlflow import sklearn as ml_sklearn
from mlflow import keras as ml_keras
from mlflow import log_artifacts, log_metric, log_metrics, log_param, log_params
def start(is_keras=1, n_estimator=20):
iris = Iris_Model()
X, y = dataLoad()
if is_keras:
tf_model, model_info = iris.keras_model(X, y, n_estimator)
log_metrics(model_info['score'])
log_params(model_info['params'])
ml_keras.log_model(tf_model, 'DNN_keras')
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
else:
model, model_info = iris.sklearn_model(X, y, n_estimator)
log_metrics(model_info['score'])
log_params(model_info['params'])
ml_sklearn.log_model(model, 'RandomforestClassifier')
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
if __name__ == "__main__":
start(1)
MLflow - Tracking
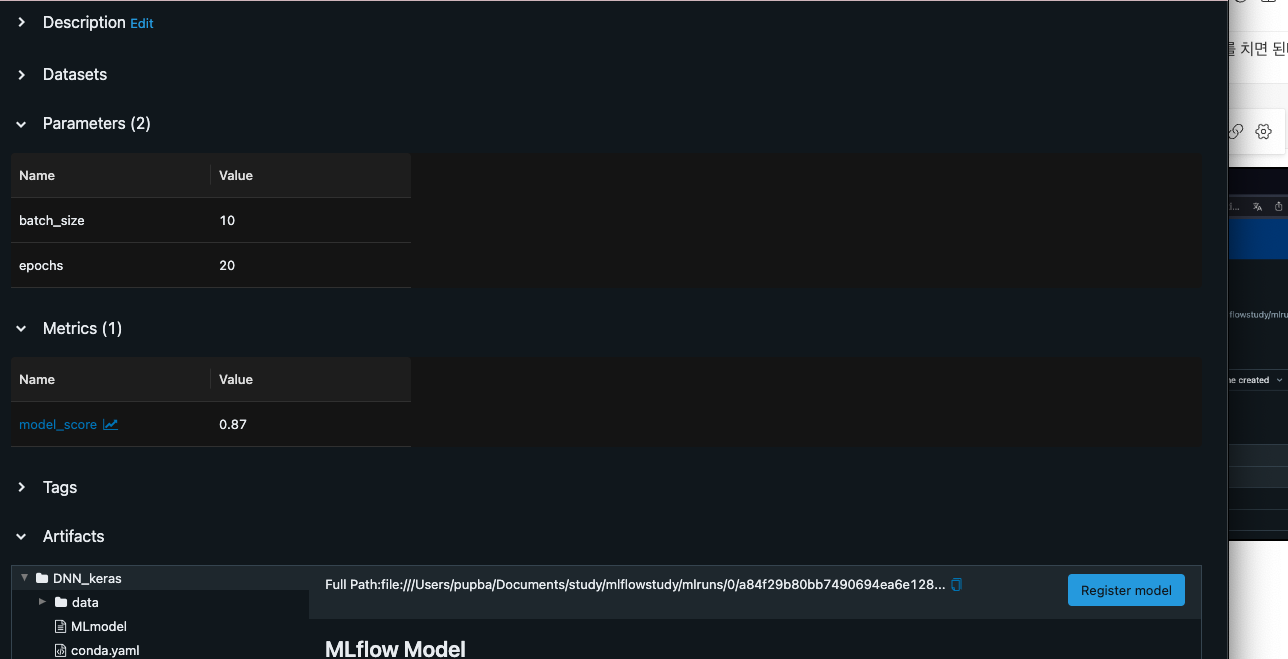
log_metric(or log_metrics)
- ML or DL 모델의 metric을 logging
- accuarcy, f1-score, precision, recall ....
log_param(or log_params)
- 모델에서 사용되는 파라미터 값을 저장
- log_param은 하나하나 저장할 때 사용하며, json 형태로 저장하고 싶으면 log_params 사용
log_model(or log_model)
- ML or DL 모델 저장
이렇게 코드를 실행하고 저장된 결과를 모니터링하는 방법은 터미널에 "mlflow ui"를 치면 된다.
mlflow ui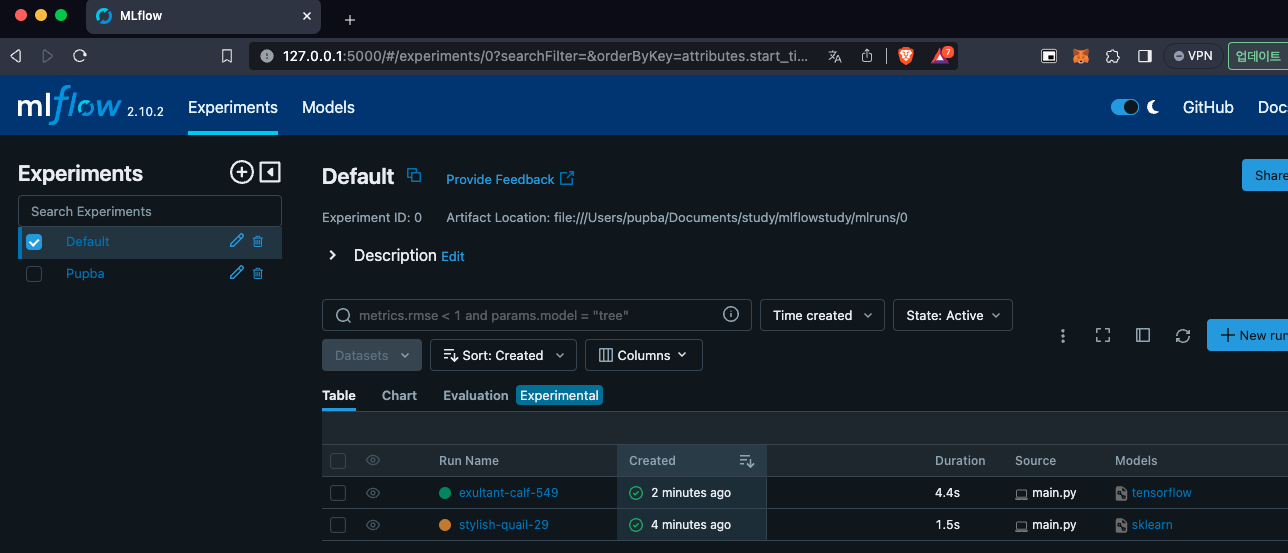
host를 변경할 수도 있다.
mlflow ui --host 0.0.0.0
or
mlflow server --host 0.0.0.0728x90
반응형
'AI > MLflow' 카테고리의 다른 글
| [MLflow] Autologging (0) | 2024.02.28 |
|---|---|
| [MLflow] MLflow Model Registry (0) | 2024.02.28 |
| [MLflow] MLflow Models (0) | 2024.02.28 |
| [MLflow] MLflow Project (0) | 2024.02.27 |
| [MLflow] MLflow Tracking (0) | 2024.02.27 |



