728x90
반응형
MySQL의 집단 함수들
GROUP BY - COUNT(), MAX(), MIN(), SUM(), AVG()
여러개의 row를 그룹화(group by)하여 숫자를 세거나 평균을 구하는 등의 기능을 하는 함수이다.
집계 명령어의 필요성
- 기존의 find로는 원하는 데이터를 가공하는데 한계가 있다.
- 빅데이터를 다루려면 새로운 데이터 가공 방식이 필요하다.
- MongoDB의 aggregation을 사용하여 grouping, fitering 등 다양한 연산을 적용할 수 있다.
MongoDB의 집계 방법론
데이터베이스의 모든 정보를 불러와 어플리케이션에서 집계하는 방법이다.
1) 맵 - 리듀스
- Javascript 함수를 정의하여 그 함수를 호출하여 집계한다.
- map 함수와 reduce 함수를 정의하여 mapReduce() 함수를 이용해 사용한다.
var map_func = function(){ // 고객별, 구매 금액 추출
emit(this.cust_id,this.price);
}
var reduce_func = function(key,value){ // 주문 가격을 더하는 처리
return Array.sum(value);
}
db.order.mapReduce(
//map
map_func,
//reduce
reduce_func,
//option
{out:"order_total"}
)
db.order_total.find()- Javascript 엔진과 데이터 교환을 위해 램 사용량이 많아진다.
- Javascript 함수를 정의해 사용하므로 자유도가 높다.
2) 집계 파이프라인
- Pipeline : 선행하는 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 구조이다.
- 출력 -> 입력 출력 -> 입력 출력
- 집계 명령어 사용 - 데이터를 미리 처리해서 작게 만들어 어플리케이션으로 전달 - 효율적이다.
- MongoDB 내부에서 집계처리를 하므로 램 용량이 많이 필요 하지 않다.
- MongoDB 내부에서 작동하기 때문에 정해진 연산자만 사용가능 - 자유도가 낮다.
- Storage engine과 가장 가까운 곳에서 연산을 하므로 가장 효율적이다.
- 맵-리듀스와 비교해 봤을 때 합리적인 처리 방법이다.
MongoDB 아키텍처

MongoDB 집계방법론 비교
| 어플리케이션 | 맵-리듀스 | 집계 파이프라인 | |
| 자유도 | 좋다 | 좋다 | 나쁘다 |
| 처리속도 | 가장 나쁘다 | 보통 | 가장 좋다 |
| 램 사용량 | 매우 높음 | 높음 | 낮음 |
| 처리 위치 | 어플리케이션 내부 | 자바스크립트 엔진 | MongoDB 내부 |
MongoDB에서 집계 파이프라인
- SQL에서의 집계 처리 예시 - 한 문장으로 해결
SELECT dept_id, AVG(salary) from employee group by (dept_id)- MongoDB에서는 이렇게 하나의 단계(명령어)로 처리하지 않는다.
- 최종 결과를 만들기 까지의 연산을 여러 개의 "스테이지( { } )"로 나누어 연산한다.
스테이지
- 각 스테이지 단계는 특정 형태의 도큐먼트를 입력 받고 "도큐먼트 스트림"을 출력한다.
- 집계 파이프라인의 개별 단계는 데이터 처리 단위이다.
- 한 번에 하나씩 도큐먼트 스트림을 가져와 처리하고, 출력 스트림을 생성한다.
- 각 단계는 knobs 또는 tunable(조정할 수 있는) 셋을 제공한다.
- tunable : 필드 수정, 산술 연산, 도큐먼트 재구성 등의 연산자의 형태이다.
- 하나의 단계가 여러 번 반복해서 포함될 수 있다.
스테이지 종류
| 스테이지 | 내용 |
| $project | 출력 도큐먼트 상에 배치할 필드 지정 (SELECT) |
| $match | 처리될 도큐먼트를 선택, find와 비슷한 역할(HAVING) |
| $limit | 다음 단계에 전달될 도큐먼트 수를 제한 |
| $skip | 지정된 수의 도큐먼트를 건너뜀 |
| $unwind | 배열을 확장하여 각 배열 항목에 대해 하나의 출력 도큐먼트를 생성 |
| $group | 지정된 키로 도큐먼트를 그룹화 함 |
| $sort | 도큐먼트를 정렬, 1: 오름차순 ,-1: 내림차순 |
| $geoNear | 지리 공간위치 근처의 도큐먼트 선택 |
| $out | 파이프라인의 결과를 컬렉션에 씀 |
| $redact | 특정 데이터에 대한 접근을 제어 |
스테이지 기술 순서
- $project -> $match -> $group -> $sort -> $skip -> $limit -> $unwind -> $out
- $project 먼저 수행 - 필요한 열(필드)을 먼저 추출하고 다음 스테이지 진행.
- $match -> $project -> $sort -> $skip -> $limit
- $match 먼저 수행 - 필요한 행(도큐먼트)을 먼저 추출하고 다음 스테이지 진행.
집계 명령어 aggregate() 형식
db.컬렉션.aggregate([
{
$match : { }//스테이지1
},
{
$project : { }//스테이지2
},
{
//스테이지..
}
]) // end of aggregate스테이지 연습
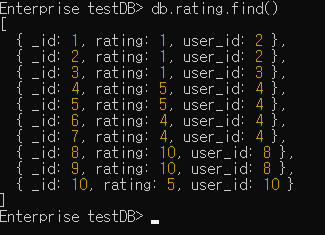
$project
//db.컬렉션.aggregate([{$project:{ }}])
db.rating.aggregate([{$project:{_id:0,rating:1,hello:"new field"}}])
// _id는 출력하지 않음
// rating은 출력
// hello 라는 필드 새로 만들어 모든 도큐먼트에 적용 - 값은 new field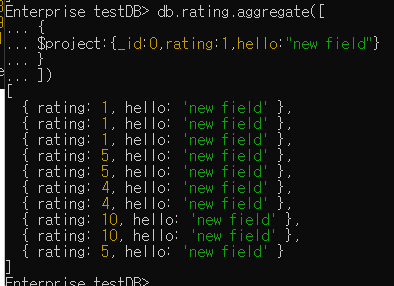
$match
//db.컬렉션.aggregate([ {$match:{ }} ])
db.rating.aggregate([{$match:{rating:{$gte:4}}}])
// rating이 4이상인 도큐먼트만 찾음
$limit
// db.컬렉션.aggregate([{$limit:개수}])
db.rating.aggregate([{$limit:5}])
// 처음부터 5개의 도큐먼트만 다음 스테이지로 전달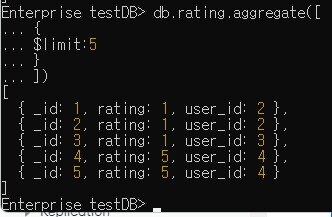
$skip
//db.컬렉션.aggregate([ { $skip: 개수 }])
db.rating.aggregate([ { $skip: 3 }])
// 처음부터 도큐먼트 3개를 건너뛰고 나머지 도큐먼트를 전달함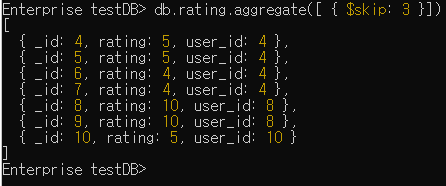
$unwind
//db.컬렉션.aggregate([{$unwind:"$배열 필드 명"}])
db.tmp.aggregate([{$unwind:"$sizes"}])
// sizes 필드의 요소들을 쪼개어 새로운 도큐먼트 생성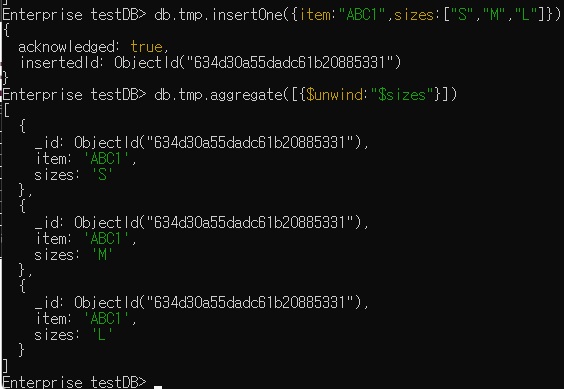
$sort
// db.컬렉션.aggregate([ { $sort: {정렬 할 기준 필드:1 or -1} }])
db.rating.aggregate([ { $sort: {rating:1} }])
// rating을 기준으로 오름차순 정렬
db.rating.aggregate([ { $sort: {_id:-1} }])
// _id를 기준으로 내림차순 정렬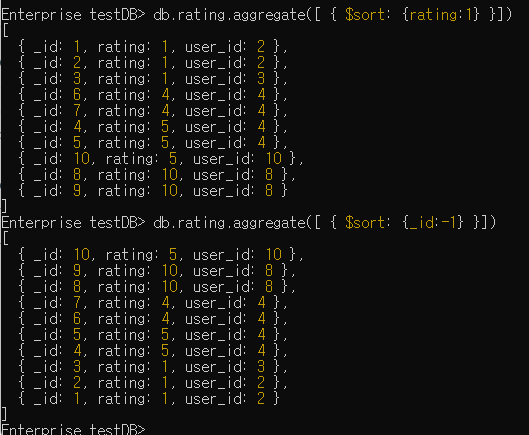
$out
db.컬렉션.aggregate([ { 스테이지},{$out:"저장할 컬렉션 이름"}])
db.rating.aggregate([ { $group: {_id:"$rating", count_rating:{$sum:1}}},{$out:"re"}])
// 앞의 스테이지의 결과를 "re"라는 컬렉션으로 저장
$group
$group과 같이 사용되는 연산자들
| 연산자 분류 | 연산자 | 설명 |
| 산술연산 | $sum | 각 문서에서 해당 필드의 값을 합함(count는 {sum:1}로 구할 수 있음) |
| $avg | 각 문서에서 해당 필드의 평균을 구함 | |
| 극한 연산 | $max | 입력값 중 최대값 반환 |
| $min | 입력값 중 최소값 반환 | |
| $first | 그룹의 첫번쨰 값 반환(보통 sort 후 사용) | |
| $last | 그룹의 마지막 값 반환(보통 sort 후 사용) | |
| 배열 연산 | $addToSet | 해당 값이 없는 경우, 배열에 추가, 순서 보장하지 않음 |
| $push | 차례대로 배열에 추가 |
$group을 사용할 때는 항상 _id 필드의 값이 있어야 한다.
_id 필드의 값 == 기준이되는 필드(없는 경우 == 전체 도큐먼트 대상 == null)
ex. _id:"$rating", _id:null
//db.컬렉션.aggregate([ { $group: {_id:"그룹을 나눌 필드",연산자들}}])
db.rating.aggregate([ { $group: {_id:"$rating", count_rating:{$sum:1}}}])
// rating 필드의 값 별로 그룹을 만든다.
// count_rating이라는 필드를 새로 만들어 값을 1로 하고 모든 도큐먼트에 적용
// $sum으로 count_rating 필드의 값들을 합친 값을 그룹별 count_rating 필드의 값으로 함.
// == 그룹별 개수 세기
스테이지의 사용 방법
각 스테이지는 작성 순서대로 하나하나 동작한다. (순차 실행)
- $project 스테이지를 단독 사용한 경우
- $project에서 선택한 필드들은 다음 스테이지의 입력이된다.
- $match 스테이지를 단독 사용한 경우
- $match 조건을 만족하는 도큐먼트의 모든 필드가 출력된다.
- $group 스테이지를 단독 사용한 경우
- 그룹핑 기준을 설정하는 기능 뿐 아니라, 쿼리의 결과에 포함될 필드를 제어하는 기능도 수행한다.
728x90
반응형
'DB > MongoDB' 카테고리의 다른 글
| [MongoDB] 15. 집계명령어 - 다양한 연산자, 뷰 (0) | 2022.12.17 |
|---|---|
| [MongoDB] 14. 집계명령어 - 고급 스테이지, 여러가지 스테이지 (0) | 2022.12.17 |
| [MongoDB] 12. 쿼리작성하기 - 정규 표현식, 문자열 연산자, Cursor, $(배열 위치 연산자), $where 연산자 (1) | 2022.10.13 |
| [MongoDB] 11. 쿼리작성하기 - 배열 요소,배열 연산자로 쿼리하기 (0) | 2022.10.09 |
| [MongoDB] 10. 쿼리작성하기 - 타입, 논리 연산자로 비교하기 (0) | 2022.10.09 |



