728x90
반응형
누산기(accumulator) 객체
여러 도큐먼트에서 찾은 필드로 부터 값을 "계산"하는 객체이다.
MongoDB 3.2 이전에는 $group 스테이지에서만 누산기 객체를 사용했지만, 이후에는 $project 스테이지에서도 배열안에서 작동한다.
원본
// 컬렉션 rating
db.rating.find()
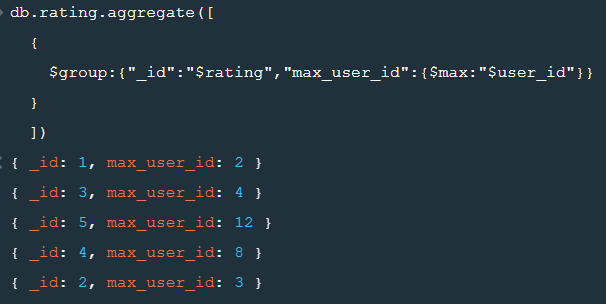
$max
- 그룹에서 해당 필드의 최댓값을 반환
db.rating.aggregate([
{
$group:{"_id":"$rating","max_user_id":{$max:"$user_id"}}
}
])
$min
- 그룹 필드에서 해당 필드의 최솟값을 반환
db.rating.aggregate([
{
$group:{"_id":"$rating","min_user_id":{$min:"$user_id"}}
}
])
$sum
- 그룹에서 해당 필드의 합산값을 반환
db.rating.aggregate([
{
$group:{"_id":"$rating",sum_user_id":{$sum:"$user_id"}}
}
])
$avg
- 그룹에서 해당 필드의 평균값을 반환
db.rating.aggregate([
{
$group:{"_id":"$rating","avg_user_id":{$avg:"$user_id"}}
}
])
$project 단계에서 사용된 누산기
db.array.find()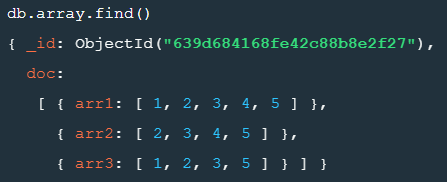
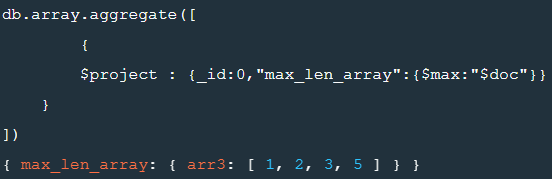
db.array.aggregate([
{
$project : {_id:0,"max_len_array":{$max:"$doc"}}
}
])
$unwind 스테이지
하나의 도큐먼트에 있는 배열 요소들을 분리하여 각각 도큐먼트에 분배하는 역할(카티션 곱 기능)
$push의 반대 기능
{키1 : "값1",키2 : "값2",키3 : ["요소1","요소2","요소3"]}
$unwind => {키1 : "값1",키2 : "값2",키3:"요소1"} {키1 : "값1",키2 : "값2",키3:"요소2"} {키1 : "값1",키2 : "값2",키3:"요소3"}
$unwind 전
db.rating.aggregate([
{
$match:{rating:{$gte:4}}
},
{
$group : {_id:"$rating",user_ids:{$push:"$user_id"}}
}
])
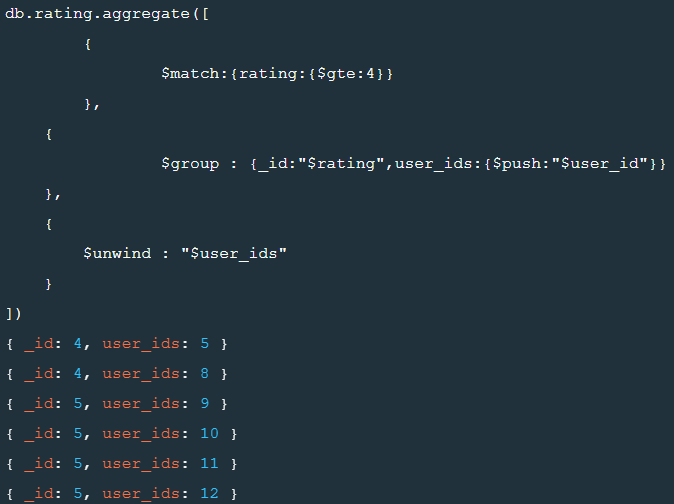
$unwind 후
db.rating.aggregate([
{
$match:{rating:{$gte:4}}
},
{
$group : {_id:"$rating",user_ids:{$push:"$user_id"}}
},
{
$unwind : "$user_ids"
}
])
$out 스테이지
입력 받은 도큐먼트를 컬렉션으로 저장
컬렉션에 저장하지 않으면 콘솔에 출력되는 것으로 질이는 끝난다.
db.rating.aggregate([
{
$group:{_id:"$rating",user_ids:{$push:"$user_id"}}
},
{
$out:"user_id_by_rating"
}
])
$sort 스테이지
요소를 정렬한다.
db.rating.aggregate([
{
$sort : {"user_id":-1}
}
])
// -1 내림차순, 1 오름차순
$skip 스테이지
출력을 입력 한 숫자 만큼 넘어간다.
db.rating.aggregate([
{
$sort : {"rating":1}
},
{
$skip: 5
}
])
$limit 스테이지
출력되는 도큐먼트 개수를 입력한 숫자 만큼 제한 한다.
db.rating.aggregate([
{
$sort : {"rating":1}
},
{
$limit: 5
}
])
고급 스테이지
| 스테이지 | 설명 |
| $bucket | 도큐먼트를 범위에 따라 그룹화 한다. - $group 스테이지는 유니크한 모든 값에 대해서 그룹 생성 - $bucket은 사용자가 임의로 각 그룹의 범위를 설정 가능 |
| $bucketAuto | 자동 그룹핑(그룹의 갯수에 따라) |
| $addFields | $project 스테이지에서 새로운 필드 추가 |
| $facet | 각 필드에 대한 서브 파이프라인 수행해서 배열로 저장 |
| $lookup | 같은 DB에 있으면서 샤딩되지 않은 외부 컬렉션에 대해, 현재 필드와 외부 필드가 일치하면 배열로 외부 컬렉션 도큐먼트를 가져옴. (Join 연산과 유사함.) |
$bucket 스테이지
$bucket:
{
groupBy: <expression>, // 버케팅 할 기준
boundaries: [ <lowerbound1>, <lowerbound2>, ... ], // 버케팅 기준값의 구간
default: <literal>, // optional. 구간 외의 도큐먼트를 처리할 필드명
output: {
<output1>: { <$accumulator expression> },
// optional. 버케팅한 후 출력 결과를 표시할 방법 ...
<outputN>: { <$accumulator expression> }
}
}db.rating.aggregate([
{
$bucket:{
groupBy:"$rating",
boundaries:[2,3,5],
default:"Others",
output : {
count : {$sum : 1},
user_ids : {$push: "$user_id"}
}
}
}
])
$bucketAuto 스테이지
- 범위를 자동으로 설정
- 전체 도큐먼트를 몇 개의 그룹으로 묶을지 설정하면, 그룹에 따라 자동으로 그룹을 실행
$bucketAuto: {
groupBy: 그룹핑 기준,
buckets : 버킷 사이즈, 필수 속성 // default 대신
output:{...}
}
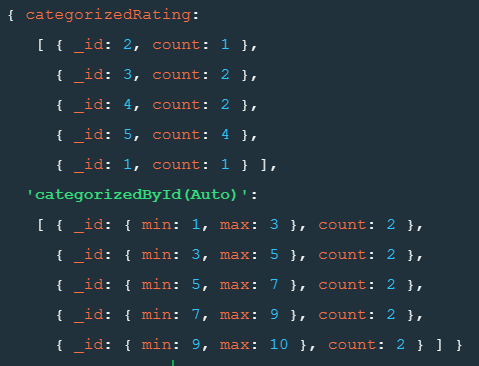
granularity : //boundaries 대신db.rating.aggregate([
{
$facet:{
categorizedRating : [
{$group : {_id:"$rating",count : {$sum:1}}}
],
"categorizedById(Auto)":[
{$bucketAuto : {groupBy:"$_id",buckets:5}}
]
}
}
])
$addFields 스테이지
db.rating.aggregate([
{
$addFields:{
hello:"world"
}
},
{$project : {hello:1}},
{$limit:4}
])
$facet 스테이지
- 하나의 쿼리로 다양한 기준의 그룹핑을 수행할 때 사용
- 카테고리별로 그룹핑하는 작업을 하나의 질의로 해결하려고 할 때
- 하나의 쿼리에 여러 개의 파이프라인({})을 나열해서 한 번의 여러 기준의 그룹핑을 수행할 수 있다.
{
$facet:
{
<outputField1>: [ <stage1>, <stage2>, ... ],
<outputField2>: [ <stage1>, <stage2>, ... ],
...
}
}
// outputField는 서프 파이프라인이라고 하고
// $bucket, $bucketAuto, $sortByCount 중 하나의 서브 스테이지를 반드시 가져야한다.db.rating.aggregate([
{
$facet:{
categorizedRating:[
{$group : {_id:"$rating",count:{$sum:1}}}
],
"categorizedById(Auto)" : [
{$bucketAuto:{groupBy:"$_id",buckets:5}}
]
}
}
])
$lookup 스테이지
https://github.com/Karoid/mongodb_tutorials - 실습 데이터
- 첫번째 형식
- from : 조인할 도큐먼트 결정
- localField : 넘겨받은 도큐먼트의 어떤 필드를 from에서 정한 도큐먼트의 필드와 매칭할지 결정
- foreignField : from에서 선택한 도큐먼트에서 어떤 필드를 localField에서 정한 필드와 매칭할 지 결정
- as : from에서 정한 도큐먼트로부터 매칭되어 가져온 데이터를 여기서 정한 데이터 필드의 배열 안에 넣음
- 두번째 형식
- pipline : from에서 설정한 컬렉션을 해당 파이프라인에 통과시킨 뒤, 출력되는 도큐먼트들을 as에서 정한 필드에 배열 요소로 연결
- let : 선택적, pipeline 파라미터에 현재 넘겨 받은 도큐먼트의 값을 비교, 대조해야할 필요성, pipeline 파라미터에 현재 도큐먼트 값을 넘길 수 있도록 변수 선언
db.by_month.aggregate([
{
$lookup:
{
from : "area",
localField : "area_id",
foreignField : "_id",
as : "area_data"
}
},
{$limit : 1}
])
- 두번째 형식 -
db.orders.aggregate([
{
$lookup:
{
from : "warehouse",
let : {order_item : "$item",order_qty:"$ordered"},
pipeline: [
{$match:
{$expr:
{$and:
[
{$eq:["$stock_item","$$order_item"]},
{$gte: ["$instock","$$order_qty"]}
]
}
}
},
{$project : {stock_item:0, _id:0}}
] ,
as : "stockdata"
}
}
])- pipeline 파라미터
- warehouses 컬렉션에서 주어진 조건에 맞는 도큐먼트만 남기게 만든다.
- stockdata 필드의 배열에 결과를 출력
- let에서 order_item과 order_qty로 설정한 두 개의 변수는 $$를 붙혀 pipeline 파라미터에서 비교에 사용됨.
$replaceRoot 스테이지
- $project 스테이지와 유사하게 도큐먼트의 모양을 바꾸는 스테이지
- 서브 도큐먼트를 도큐먼트 전체의 내용으로 바꿀 때 유용함.
db.by_month.aggregate([
{
$addFields:{
"month_data.city_or_province":"$city_or_province",
"month_data.country":"$county"
}
},
{
$replaceRoot: {newRoot:{$arrayElemAt : ["$month_data",0]}}
}
])
기존의 month_data의 값에 지역정보(city_or_province, country)가 같이 출력됨.
$sample 스테이지
- 주어진 도큐먼트들을 랜덤하게 정해진 수대로 고르고자 할 때 사용함.
- 도큐먼트 중 몇 개의 샘플을 고르는 스테이지
db.rating.aggregate([
{
$sample:{size:3}
}
])
$sortByCount 스테이지
- 주어진 필드의 값이 같은 도큐먼트들 끼리 그룹화
- 도큐먼트의 숫자를 셈
- 내림 차순 정렬
db.rating.aggregate([{$sortByCount:"$rating"}])
728x90
반응형
'DB > MongoDB' 카테고리의 다른 글
| [MongoDB] 16. 집계명령어 - 트랜잭션 (0) | 2022.12.18 |
|---|---|
| [MongoDB] 15. 집계명령어 - 다양한 연산자, 뷰 (0) | 2022.12.17 |
| [MongoDB] 13. 집계명령어 - aggregate, $project, $match, $group (0) | 2022.10.17 |
| [MongoDB] 12. 쿼리작성하기 - 정규 표현식, 문자열 연산자, Cursor, $(배열 위치 연산자), $where 연산자 (1) | 2022.10.13 |
| [MongoDB] 11. 쿼리작성하기 - 배열 요소,배열 연산자로 쿼리하기 (0) | 2022.10.09 |



