Pupbani는 과일 분류 비지도학습 모델을 완성하였다.
하지만 이 모델을 사용하여 분류한 사진들을 저장하다보니 용량이 너무 많아져 저장 공간이 부족해졌다.
마케팅 팀장은 Pupbani에게 나중에 분류에 영향을 끼지지 않으면서 업로드된 사진의 용량을 줄이는 방법은 없을까 하고 물어 봤다.
Pupbani는 그 질문에 차원축소를 사용해보겠다고 답한 후 차원축소 알고리즘을 작성하러 떠났다.
차원과 차원축소
지금까지 우리는 데이터가 가진 속성을 특성이라고 불렀다.
과일 사진의 경우 10,000개의 픽셀(100 x 100)이 있기 때문에 10,000개의 특성이 있다고 생각하면 된다.
머신러닝에서는 이러한 특성을 차원(dimension)이라고도 부른다.
차원의 저주(Curse of Dimentionality)

- 1차원에서 특성이 3개가 있다고 가정
- 2차원에서는 이 특성이 3^2가 된다.
- 차원이 늘어날 수록 특성의 개수가 기하급수 적으로 증가한다.
- 특성의 개수가 늘어날 수록 동일 데이터를 설명하는 빈 공간이 증가함.
- 이러한 특징들 때문에 모델링 과정에서의 공간적, 시간적 자원이 많이 들어감.
이러한 차원을 줄일 수 있다면 저장 공간을 크게 절약할 수 있다.
차원을 줄이는 방법으로 비지도 학습 중 하나인 차원 축소 알고리즘을 사용한다.차원 축소 알고리즘은 데이터를 가장 잘 나타내는 일부 특성을 선택하여 데이터 크기는 줄이고 지도 학습 모델의 성능을 향상 시킬 수 있다.줄어든 차원을 원본 손실을 최소로 하면서 복원할 수 있다.대표적인 알고리즘은 PCA(Principal Component Analysis, 주성분 분석)이다.
PCA 주성분 분석
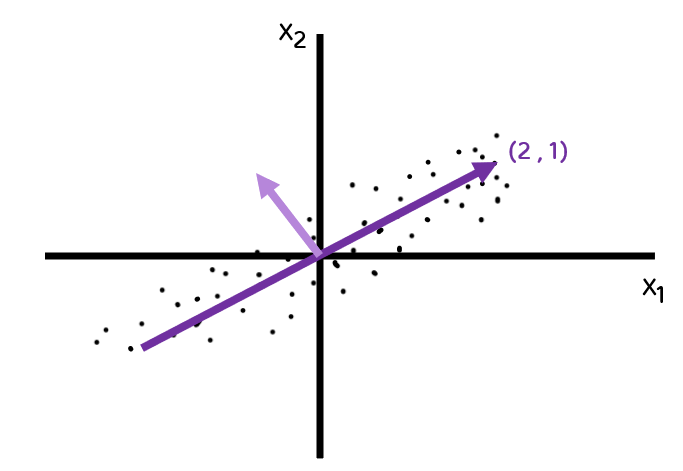
주성분 분석은 데이터에 있는 분산이 큰 방향을 찾는 것 이다.
분산은 데이터가 널리 퍼져 있는 정도를 말한다.
다음의 데이터가 있을 때
이 데이터는 2개의 특성을 가지고 있다.
이 데이터의 분산이 가장 큰 방향을 표시 해 보겠다.
이 직선이 원점에서 출발한다면 두 원소로 이루어진 벡터로 쓸 수 있다.
ex) (2,1)
(2,1)와 같은 벡터를 주성분(Principal Component)라고 부른다.
이 주성분 벡터는 원본 데이터에 있는 어떤 방향이다.
벡터의 원소 개수는 원본 데이터셋에 있는 특성 개수와 같다.
원본 데이터를 주성분에 직각으로 투영하여 1차원 데이터로 차원을 축소할 수 있다.
그림과 같이 S(2,4)를 주성분에 직각으로 투영하여 P(4.5)라는 1차원 데이터로 차원 축소했다.
첫번째 주성분을 찾은 뒤 이 벡터에 수직이고 분산이 가장 큰 다음 방향을 찾는다.
이렇게 찾은 벡터가 두번째 주성분이다.
일반적으로 주성분은 원본 특성의 개수 만큼 찾을 수 있다.
이제 PCA를 사용해서 차원 축소를 해보자.
PCA 클래스
데이터를 준비한다.
2차원 배열의 형태로 만들어 줘야한다.
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)PCA 클래스를 불러온다.
- PCA 클래스는 sklearn.decomposition 모듈아래 있다.
- 객체 생성 시 n_components 매개변수에 주성분 개수를 지정해야 한다.
from sklearn.decomposition import PCA
pca = PCA(n_components=50)
pca.fit(fruits_2d)PCA 클래스가 찾은 주성분은 components_ 속성에 저장되어 있다.
print(pca.components_.shape)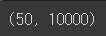
n_components를 50으로 지정했기 때문에 첫번째 값인 차원이 50개(= 주성분이 50개)이다.
두번째 차원은 항상 원본 데이터의 특성 개수와 같은 10,000개이다.
n_components에는 원하는 설명된 분산의 비율을 입력할 수도 있다.
pca = PCA(n_components=0.5)
pca.fit(fruits_2d)
print(pca.n_components_)
비율은 0~1 사이의 값을 넣으면 된다.
0.5는 설명된 분산의 50%에 달하는 주성분을 찾도록 설정한 것이다.
PCA 클래스는 50%에 달하는 주성분을 찾을 때까지 자동으로 주성분을 찾는다.
몇 개의 주성분을 찾았는지는 n_components_를 출력하면 알 수 있다.
주성분을 이미지로 출력해 보자.
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr) # n은 샘플 개수입니다
# 한 줄에 10개씩 이미지를 그립니다. 샘플 개수를 10으로 나누어 전체 행 개수를 계산합니다.
rows = int(np.ceil(n/10))
# 행이 1개 이면 열 개수는 샘플 개수입니다. 그렇지 않으면 10개입니다.
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows, cols,
figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i*10 + j < n: # n 개까지만 그립니다.
axs[i, j].imshow(arr[i*10 + j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
draw_fruits(pca.components_.reshape(-1, 100, 100))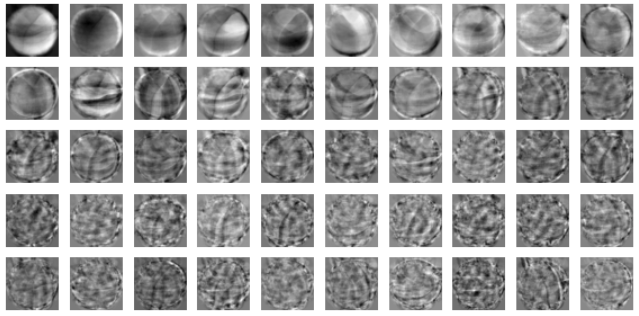
주성분을 찾았으므로 원본 데이터를 주성분에 투영하여 10,000개의 특성을 50개로 줄일 수 있다.
transform() 메서드를 사용해 원본 데이터의 차원을 줄일 수 있다.
print("차원 축소 전 데이터 형태:",fruits_2d.shape)
fruits_pca = pca.transform(fruits_2d)
print("차원 축소 후 데이터 형태:",fruits_pca.shape)
원본 데이터 재구성
앞에서 차원을 축소한 데이터를 원본 데이터로 재구성할 수 있다.
차원 축소로 인해 어느정도 손실은 발생할 수 밖에 없다.
하지만 최대한 분산이 큰 방향으로 데이터를 투영했기 때문에 원본 데이터를 상당 부분 재구성할 수 있다.
PCA 클래스의 inverse_transform() 메서드를 통해 재구성을 할 수 있다.
fruits_inverse = pca.inverse_transform(fruits_pca)
print("원본 데이터로 재구성된 데이터 :",fruits_inverse.shape)
복원된 데이터를 시각화 해보자.
fruits_reconstruct = fruits_inverse.reshape(-1, 100, 100)
for start in [0, 100, 200]:
draw_fruits(fruits_reconstruct[start:start+100])
print("\n")


설명된 분산
주성분이 원본 데이터 분산을 얼마나 잘 나타내는지 기록한 값을 "설명된 분산(Explained Variance)"이라고 한다.
PCA 클래스의 explained_variance_ratio_에 기록되어 있다.
print(np.sum(pca.explained_variance_ratio_))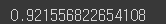
92%가 넘는 분산을 유지하고 있다.
설명된 분산을 시각화 해보자.
plt.plot(pca.explained_variance_ratio_)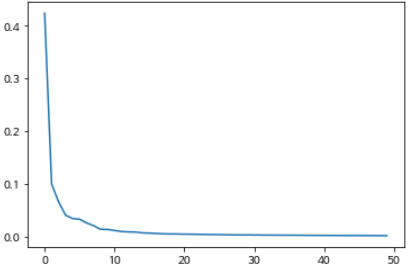
그래프를 보면 처음 10개의 주성분이 대부분의 분산을 표현하고 있다.
그 다음 부터는 각 주성분이 설명하고 있는 분산은 비교적 작다.
다른 알고리즘과 함께 사용하기
차원 축소된 데이터를 사용하여 지도학습 모델을 학습해보자.
로지스틱 회귀 모델을 사용해보겠다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()타겟 데이터를 생성한다.(0: 사과, 1: 파인애플, 2: 바나나)
target = np.array([0] * 100 + [1] * 100 + [2] * 100)먼저 원본 데이터로 분류를 해보자 - 모델 성능을 가늠해 보기 위해 cross_validate() 교차 검증 사용
from sklearn.model_selection import cross_validate
scores = cross_validate(lr, fruits_2d, target)
print("원본 데이터 테스트 세트 점수 :",np.mean(scores['test_score']))
print("원본 데이터 훈련 시간 :",np.mean(scores['fit_time']))
점수는 약 0.997, 훈련 시간은 1.819초 정도로 길게 나왔다.
PCA로 차원 축소한 데이터로 학습을 해보겠다.
scores = cross_validate(lr, fruits_pca, target)
print("차원 축소 데이터 테스트 세트 점수 :",np.mean(scores['test_score']))
print("차원 축소 데이터 훈련 시간 :",np.mean(scores['fit_time']))
특성을 50개만 사용했는데 점수가 100%이고 훈련시간도 0.024 정도로 매우빠르다.
위에서 2개의 주성분을 찾은 데이터로 테스트를 해보자.
scores = cross_validate(lr, fruits_pca, target)
print("차원 축소 데이터 테스트 세트 점수 :",np.mean(scores['test_score']))
print("차원 축소 데이터 훈련 시간 :",np.mean(scores['fit_time']))
놀랍게도 2개의 주성분만으로도 99%의 정확도가 나온다.
이번에는 PCA로 차원축소한 데이터로 K-Means를 사용해 클러스터를 찾아보자.
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_pca)
result = np.unique(km.labels_, return_counts=True)
print(f"0번 샘플 개수: {result[1][0]}개")
print(f"1번 샘플 개수: {result[1][1]}개")
print(f"2번 샘플 개수: {result[1][2]}개")
for label in range(0, 3):
draw_fruits(fruits[km.labels_ == label])
print("\n")



이제 이 데이터를 산점도로 그려보자.
데이터 특성의 수가 적기 떄문에 화면에 출력이 비교적 쉽다.
for label in range(0, 3):
data = fruits_pca[km.labels_ == label]
plt.scatter(data[:,0], data[:,1])
plt.legend(['사과', '바나나', '파인애플'],loc="upper center")
plt.show()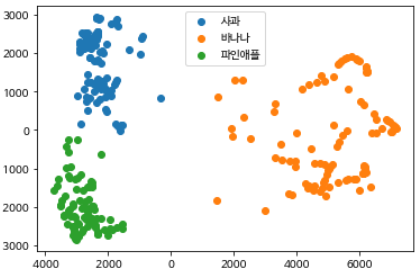
산점도 아주 잘 구분되게 그려진다.
이렇게 데이터 시각화를 통해 데이터에 대한 통찰을 얻을 수 있다.
- 사과와 파인애플 데이터는 서로 가까이 붙어 있어 몇 개가 혼동 될 수 있을 것 같다.
Pupbani는 차원 축소를 통해 데이터의 용량을 줄이고 나아가 학습 모델의 성능까지 끌어올리는 결과를 달성하였다.
'AI > 기계학습(Machine Learning)' 카테고리의 다른 글
| [기계학습/ML]16. SVM(Support Vector Machine) 서포트 벡터 머신 (0) | 2022.12.10 |
|---|---|
| [기계학습/ML]14. 비지도학습 - K-평균(K-Means) (1) | 2022.12.05 |
| [기계학습/ML]13. 비지도학습 - 군집(Clustering) (0) | 2022.12.05 |
| [기계학습/ML]12. 앙상블 학습 - 랜덤 포레스트, 엑스트라 트리, 그레이디언트 부스팅 (0) | 2022.10.24 |
| [기계학습/ML]11. 검증 세트 - 교차 검증, 그리드 서치 (0) | 2022.10.24 |



