이전 글에서는 순환 신경망의 개념과 동작 원리를 알아봤다.
이제 이 순환 신경망을 사용해 IMDB리뷰 데이터를 분류해보자.
※ 자연어 처리(NLP,Natural Language Processing)
- 컴퓨터를 사용해 인간의 언어를 처리하는 분야이다.
- 대표적으로 음성 인식, 기계 번역, 감성 분성(IMDB리뷰 분석) 등이 있다.
- 훈련 데이터를 종종 말뭉치(corpus)라고 부른다.
IMDB리뷰 데이터 세트
유명한 인터넷 영화 DB인 imdb.com에서 수집한 리뷰를 감상평에 따라 긍정/부정으로 분류해 놓은 데이터 셋이다.
총 50,000개의 샘플로 이루어져 있다.
- 훈련/테스트 세트 데이터는 각각 25,000개씩 나누어져 있다.
- 긍정/부정 리뷰 데이터는 각각 25,000개씩 나누어져 있다.

신경망에 텍스트를 전달할 때 바로 전달하지 않는다.
데이터에 등장하는 단어마다 고유한 정수를 부여하여 전달한다.
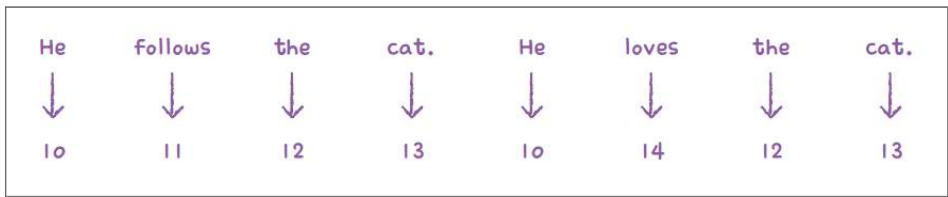
이렇게 부여한 정수를 토큰(Token)이라고 부른다.
- 하나의 샘플은 여러 개의 토큰으로 이루어져 있고 1개의 토큰이 하나의 타임 스탬프에 해당한다.
- 어휘 사전 : 훈련 세트에서 고유한 단어를 뽑아 만든 목록(ex. 테스트 세트 안에 어휘 사전에 없는 단어가 있다면 2로 변환 하여 신경망 모델에 주입)
- 예약된 토큰 : 토큰 중 몇 개는 특정 용도로 예약되어 있다.(0:패딩, 1: 문장의 시작, 2: 어휘사전에 없는 토큰)
텐서플로는 IMDB 리뷰 데이터셋은 영어로 된 문장이지만 편리하게도 텐서플로에는 이미 정수로 바꾼 데이터가 포함되어 있있다.
- tensorflow.keraas.datasets 패키지 아래 imdb모듈을 임포트 하면 된다.
- load_data() 함수의 num_words 매개변수로 자주 등장하는 단어의 개수를 조절할 수 있다.
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(
num_words=500)
print(train_input.shape, test_input.shape)
print("리뷰1의 길이 :",len(train_input[0]))
print("리뷰2의 길이 :",len(train_input[1]))
print("리뷰1의 값들들")
print(train_input[0])
어휘 사전에 500개의 단어만 들어가 있으므로 그외의 단어들은 모두 2로 표시된다.
# 0은 부정, 1은 긍정
print("타깃 데이터 :",train_target[:20])
이제 데이터를 훈련 세트와 검증 세트를 떼어 놓아보자.
80% 훈련(20,000개) , 20% 검증(5,000개)
from sklearn.model_selection import train_test_split
train_input, val_input, train_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)
평균적인 리뷰 길이, 짧은 리뷰의 길이, 가장 긴 리뷰의 길이를 확인해보자.
먼저 리스트 내포를 통해 train_input의 원소의 길이를 순회하며 재보자.
import numpy as np
lengths = np.array([len(x) for x in train_input])그리고 mean(), median() 함수를 통해 리뷰 길이의 평균값과 중간값을 얻어보자.
print("평균값:",np.mean(lengths))
print("중간값:", np.median(lengths))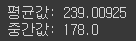
리뷰의 평균 단어 개수는 239개이고 중간값이 178이다.
이제 lengths 배열을 히스토그램으로 시각화해보자.
import matplotlib.pyplot as plt
plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()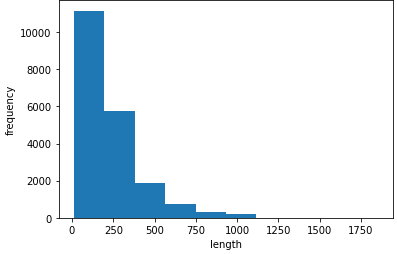
대부분의 리뷰 길이가 300미만이다.
평균이 중간값보다 높은 이유는 오른쪽 끝에 아주 큰 데이터가 있기 때문이다.
어떤 리뷰는 1000개의 단어가 넘어가기도 한다.
리뷰는 대부분 짧기 때문에 이 예제에서는 중간값보다 훨씬 짧은 100개의 단어만 사용하자.
하지만 여전히 100개의 단어보다 작은 리뷰가 있다.
이러한 리뷰들의 길이를 100에 맞추기 위해 패딩이 필요하다.
패딩을 나타내는 토큰은 0을 사용한다.
케라스는 시퀀스 데이터의 길이를 맞추는 pad_sequences() 함수를 제공한다.
- 이 함수를 사용해 train_input의 길이를 100으로 맞춰보자.
- maxlen 매개변수에 원하는 길이를 지정하면 이보다 긴 경우는 잘라내고 짧은 경우는 0으로 패딩한다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen=100)
print(train_seq.shape)
print(train_seq[5])
패딩이 된것을 확인할 수 있다.
이제 검증세트도 처리를 해주자.
val_seq = pad_sequences(val_input, maxlen=100)데이터 준비가 끝났다.
이제 신경망을 만들어보자.
순환 신경망 만들기
케라스는 여러가지 순환층 클래스를 제공한다.
그 중에 가장 간단한 것은 SimpleRNN 클래스 이다.
SimpleRNN을 사용해 모델을 만들어보자.
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 500)))
model.add(keras.layers.Dense(1, activation='sigmoid'))- SimpleRNN
- 8개의 뉴런을 사용한다.
- 입력차원은 (100,500)으로 설정한다.
- 활성화 함수를 미지정하면 기본값인 'tanh'로 하이퍼볼릭 탄젠트 함수를 사용한다.
- Dense
- 1개의 뉴런 사용한다.
- 활성화 함수 sigmoid를 사용한다.
input_shape의 500이란 숫자는 어디서 나온 것 일까?
train_seq와 val_seq에 한 가지 큰 문제가 있다.
- 토큰을 정수로 변환한 이 데이터를 신경망에 주입하면 큰 정수가 큰 활성화 출력을 만든다.
- 이 정수 사이에는 어떤 관련도 없다.
- 예를 들어 20번 토큰을 10번 토큰보다 더 중요시해야 할 이유가 없다.
따라서 단순한 정숫값을 신경망에 입력하기 위해서는 다른 방식을 찾아야한다.
원핫 인코딩을 통해 해결할 수 있다.
데이터에 원핫 인코딩을 해보자.
케라스는 keras.utils 패키지 아래에 있는 to_categorical() 함수다.
- 정수 배열을 입력하면 자동으로 원-핫 인코딩된 배열을 반환해 준다.
train_oh = keras.utils.to_categorical(train_seq)
print(train_oh.shape)
print(train_oh[0][0][:12])

같은 방식으로 val_seq도 원-핫 인코딩으로 바꾸어 보자.
val_oh = keras.utils.to_categorical(val_seq)앞에 만든 모델의 구조를 출력해보자.
model.summary()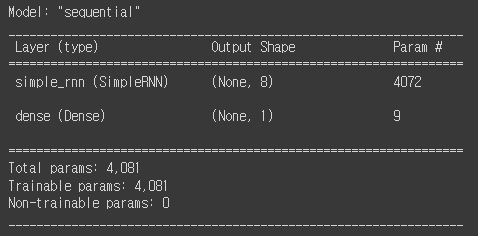
입력 데이터는 (100,500)지만 순환층은 마지막 타임스텝의 은닉 상태만 출력하므로 출력 크기가 순환층의 뉴런 개수와 동일한 8이다.
- 500차원의 원-핫 인코딩 배열이 순환층의 8개의 뉴런과 완전히 연결되기 때문에 500 x 8 = 4000개의 가중치를 가진다.
순환층의 은닉 상태는 다시 다음 타임스텝에 사용되기 때문에 또 다른 가중치와 곱해진다.
- 이 은닉 상태도 순환층의 뉴런과 완전히 연결되기 때문에 8(은닉 상태 크기) x 8(뉴련 개수) = 64개의 가중치가 필요하다.
마지막으로 뉴런마다 1개의 절편이 있으므로 8개의 절편을 가진다.
결과적으로 순환층의 파라미터의 개수는 총 4072개 이다.
4072 = 500 x 8 + 8 x 8 + 8 = 4000 + 64 + 8
순환 신경망 훈련하기
만들어진 순환 신경망 모델을 컴파일 해보자.
이 예제에서는 RMSprop의 학습률 0.001을 사용하지 않기 위해 learning_rate를 0.0001로 지정하였다.
- 에포크 수 : 100
- 배치 크기 : 64
- 체크포인트, 조기종료 추가
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)원-핫 인코딩을 한 데이터들로 학습을 진행해보자.
history = model.fit(train_oh, train_target, epochs=100, batch_size=64,
validation_data=(val_oh, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])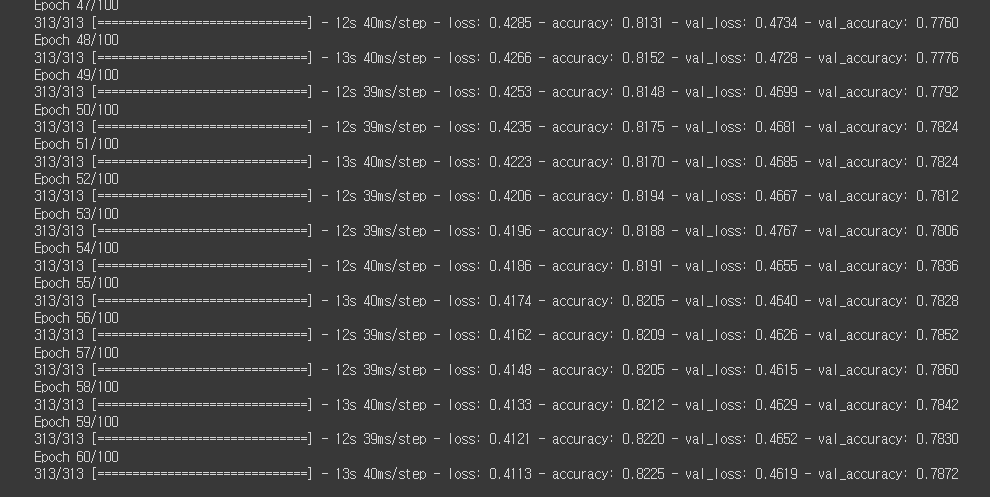
60번쨰 에포크에서 조기 종료되었다.
검증 세트의 정확도는 약 82%이다,.
훈련 손실과 검증 손실 그래프를 그려서 훈련 과정을 살펴보자.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()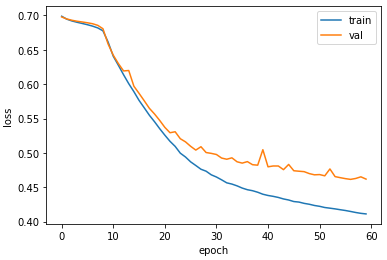
※ 원-핫 인코딩의 단점은 입력 데이터가 엄청 커진다는 것이다.
토큰 1개를 500차원으로 늘렸기 때문에 약 500배가 커진다.
이는 좋은 방법이 아니다.
순환 신경망에 사용하기 좋은 방법을 찾아보자.
단어 임베딩을 사용하기
순환 신경망에서 텍스트를 처리할 때 즐겨 사용하는 방법은 단어 임베딩(Word Embedding)이다.
단어 임베딩은 각 단어를 고정된 크기의 실수 벡터로 바꾸어 준다.

원핫 인코딩과 다르게 모든 값들이 의미 있는 값으로 채워져 있기 때문에 자연어 처리에 있어 더 좋은 성능을 내는 경우가 많많다.
케라스는 keras.layers 패키지 아래 Embedding 클래스로 임베딩 기능을 제공한다.
- 이 클래스는 다른 층처럼 모델에 추가하면 처음에는 모든 벡터가 랜덤하게 초기화 되지만 훈련을 통해 데이터에서 좋은 단어 임베딩을 학습한다.
- 입력으로 정수 데이터를 받을 수 있어 train_seq를 사용할 수 있다.
- 원-핫 인코딩(100,500)과 달리 (100,16)의 작은 크기로 2차원으로 늘리지만 더 단어를 잘 표현할 수 있다.
em_layer = keras.layers.Embedding(500, 16, input_length=100)- 첫 번째 매개변수는 어휘사전의 크기 이다.
- 두 번째 매개변수는 임베딩 벡터의 크기이다,
- 세 번째 매개변수는 입력 시퀀스의 길이이다.
모델을 만들고 구조를 출력해보자.
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(500, 16, input_length=100))
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation='sigmoid'))
model2.summary()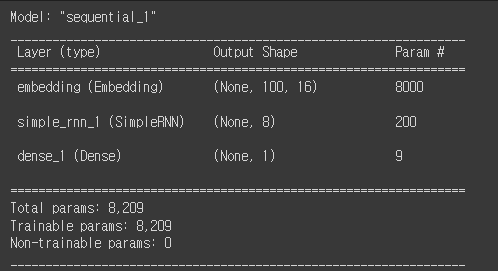
층별 파라미터를 계산 해보자
- Embedding 층 : 500개의 각 토큰을 크기가 16인 벡터로 변경한다.
- 500 X 16 = 8,000개
- SimpleRNN 층 : 임베딩 벡터의 크기가 16, 8개의 뉴런
- 16 x 8 =128 , 8 x 8 = 64, 절편 8개 , 128+64+8 = 200개
- Dense 층 : 이전 층의 출력 개수 8개 + 절편 1 = 9개
총 8000 + 200 + 9 = 8209개의 파라미터를 가진다.
모델을 컴파일 하고 모델을 학습해보자.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-embedding-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model2.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])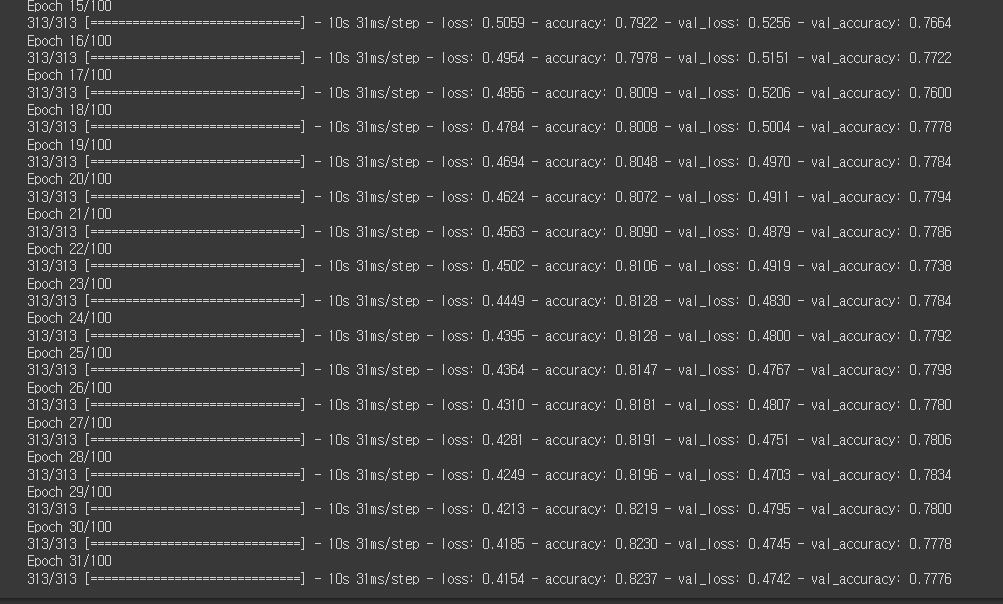
순환층의 가중치 개수가 더 작고 훈련 세트 크기도 훨씬 줄어 들었다.
훈련 세트의 정확도가 82%로 원-핫 인코딩의 결과와 비슷하다.
마지막으로 훈련 손실과 검증 손실을 그래프로 출력해보자.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()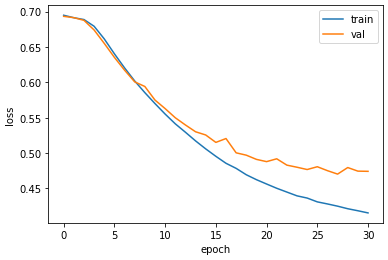
검증 손실이 더 이상 감소되지 않아 훈련이 적절히 조기종료 된 것 같다.
하지만 훈련 손실은 계속 감소한다.
더 개선할 방법을 찾아보자.
'AI > 딥러닝(Deep Learning)' 카테고리의 다른 글
| [딥러닝/DL] Loss Surface (0) | 2024.01.09 |
|---|---|
| [딥러닝/DL]9. LSTM과 GRU 셀 (0) | 2022.12.09 |
| [딥러닝/DL]7. 순차 데이터와 순환 신경망 (1) | 2022.12.08 |
| [딥러닝/DL]6. 합성곱 신경망의 시각화 (0) | 2022.12.08 |
| [딥러닝/DL]5. 합성곱 신경망을 사용한 이미지 분류 (1) | 2022.12.08 |



