Pupbani는 저번에 만든 순환 신경망의 성능을 더 끌어 올리기 위한 방법을 찾던 중
LSTM과 GRU 셀을 알게 되었다.
Pupbani는 이것들을 사용해 순환 신경망 모델을 만들어보려고 한다.
LSTM 구조
LSTM(Long Short-Term Memory)는 단기 기억을 오래 기억하기 위해 고안되었다.
LSTM은 구조가 복잡하므로 딘계적으로 따라가보자.
은닉상태 만들기
입력과 이전 타임스텝의 은닉 상태를 가중치에 곱한 후 활성화 함수를 통과 시켜 다음 은닉 상태를 만든다.
이 때 기본 순환층과 달리 "Sigmoid" 함수를 활성화 함수로 사용한다.

이 그림에서는 가중치 wx와 wh를 통틀어 wo(입력과 은닉상태를 가중치에 곱한 값)라고 부른다.
파란색 원은 tanh 함수, 빨간색 원은 시그모이드 함수, x는 곱셈을 가리킨다.
LSTM은 순환되는 상태가 2개이다.
- 은닉 상태
- 셀 상태(cell state) : 다음 층으로 전달되지 않고 LSTM 셀에서만 순환만 되는 값이다.
셀 상태 만들기
셀 상태를 구하는 과정(셀상태 : c)
- 1. 입력과 은닉 상태를 또 다른 가중치 wf에 곱한 다음 시그모이드 함수를 통과 시킨다.
- 2. 이전 타임스텝의 셀 상태와 곱하여 새로운 셀 상태를 만든다.
이 셀 상태가 오른쪽에서 tanh 함수를 통과하여 새로운 은닉 상태를 만드는 데 기여한다.
LSTM은 마치 작은 셀을 여러 개(4개) 포함하고 있는 큰 셀과 같다.
※ 은닉 상태에 곱해지는 가중치 wo와 wf가 다르고 두 셀은 각기 다른 기능을 위해 훈련된다.
- 3. 입력과 은닉 상태를 각기 다른 가중치에 곱한 다음, 하나는 (wi)시그모이드, 하나는 (wj)tanh 함수를 통과 시킨다.
- 4. 시그모이드를 통과한 wi와 tanh를 통과한 wj를 곱한 후 셀 상태와 더한다.
- 5. 이 결과가 최종적인 다음 셀 상태가 되고, 다음 은닉 상태에도 사용된다.
그림에 있는 "X(곱셈)"을 위치에 따라 삭제, 입력, 출력 게이트(gate)라고 부른다.
- 삭제 게이트 : 셀 상태에 있는 정보를 제거하는 역할을 한다.
- 입력 게이트 : 새로운 정보를 셀 상태에 추가하는 역항을 한다.
- 출력 게이트 : 이 셀 상태가 다음 은닉 상태로 출력 된다.
LSTM 신경망 훈련하기
keras는 LSTM 클래스를 지원한다.
기존 SimpleRNN 클래스 자리를 LSTM 클래스로 바꾸기만 하면된다.
- 데이터 가져오기
from tensorflow.keras.datasets import imdb
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = imdb.load_data(
num_words=500)
train_input, val_input, train_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)- 데이터 전처리(시퀀스)
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen=100)
val_seq = pad_sequences(val_input, maxlen=100)- 모델 생성
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.Embedding(500, 16, input_length=100))
model.add(keras.layers.LSTM(8))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()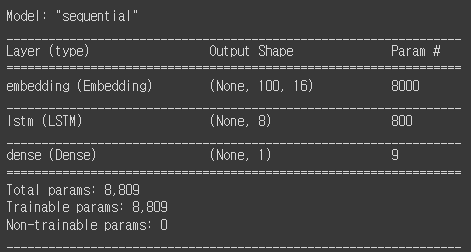
- Embedding 층: 500 x 16 = 8000개 파라미터, 어휘 사전 크기(토큰 개수) x 임베딩 벡터 크기
- LSTM 층: (16 x 8 + 8 x 8 + 8) x 4 = 800, 한개의 셀 파라미터 x 4개
- Dense 층 : 8 + 1 = 9, 이전 층 출력 개수 + 절편
※ LSTM 셀의 모델 파라미터 수는 RNN 셀의 4배
- 모델 컴파일
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])- 모델 학습
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-lstm-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
44번째 에포크에서 조기 종료 되었다.
훈련 정확도 82%, 검증 정확도 79% 이다.
- 훈련 손실과 검증 손실 그래프
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()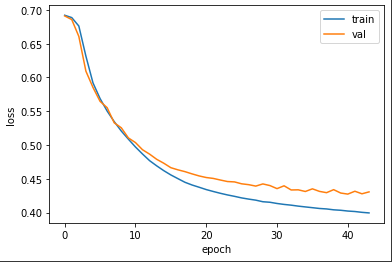
그래프를 보면 기본 순환층보다 LSTM이 과대적합을 억제하면서 훈련을 잘 수 행한 것을 볼 수 있다.
하지만 과대적합을 더 강하게 제어할 필요 있다.
그러기 위해 드롭아웃을 순환층에도 적용해보자.
- 순환 신경망 모델들은 자체적으로 드롭아웃 기능을 제공한다.
- dropout 매개변수 : 셀의 입력에 드롭아웃을 적용, 드롭 아웃 비율을 지정한다.
- recurrent_dropout 매개변수 : 순환되는 은닉상태에 드롭아웃을 적용, GPU를 사용하여 속도가 매우 느려 진다.
드롭아웃 비율 30%을 적용한 모델을 작성하자.
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(500, 16, input_length=100))
model2.add(keras.layers.LSTM(8, dropout=0.3))
model2.add(keras.layers.Dense(1, activation='sigmoid'))모델을 훈련해보자.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-dropout-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model2.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])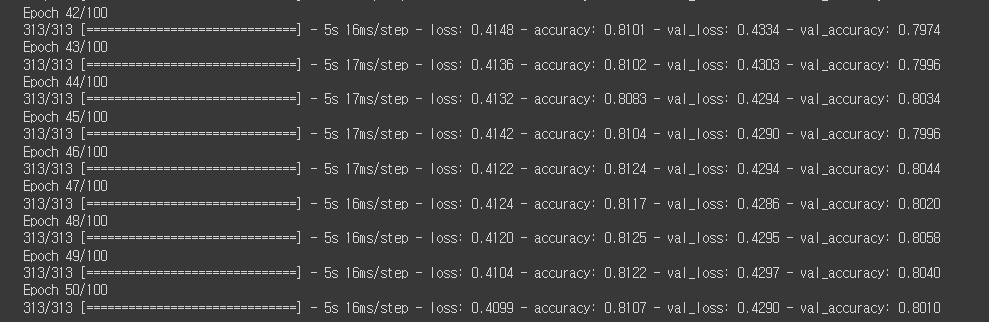
훈련 손실과 검증 손실 그래프를 그려보자.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()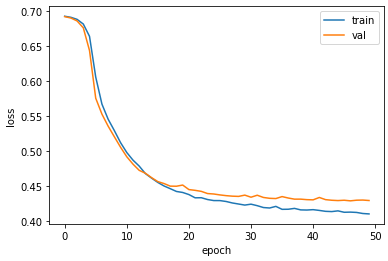
2개의 층을 연결하자
순환층을 연결할 때는 주의할 점이 있다.
- 순환층의 은닉 상태는 샘플의 마지막 타임스텝에 대한 은닉 상태만 다음 층으로 전달한다.
- 순환층을 쌓게 되면 모든 순환층에 순차 데이터가 필요하다.
- 앞쪽의 순환층이 모든 타임스텝에 대한 은닉 상태를 출력해야 한다.
- 오직 마지막 순환층만 마지막 타임스텝의 은닉 상태를 출력해야 한다.
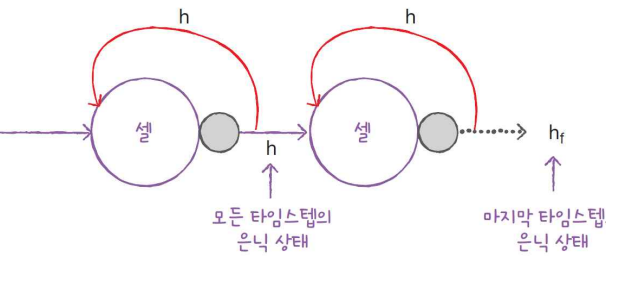
모델을 만들어보자.
model3 = keras.Sequential()
model3.add(keras.layers.Embedding(500, 16, input_length=100))
model3.add(keras.layers.LSTM(8, dropout=0.3, return_sequences=True))
model3.add(keras.layers.LSTM(8, dropout=0.3))
model3.add(keras.layers.Dense(1, activation='sigmoid'))
model3.summary()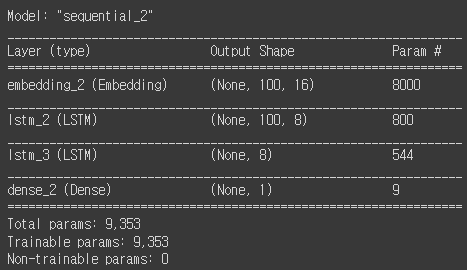
모델을 학습해보자.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model3.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-2rnn-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model3.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
일반적으로 순환층을 쌓으면 성능이 높아지나 이 예제에서는 그렇게 높은 성능이 나오지 않았다.
과대적합이 잘 제어 되었는지 확인하기 위해 훈련 손실, 검증 손실 그래프를 그려보자.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()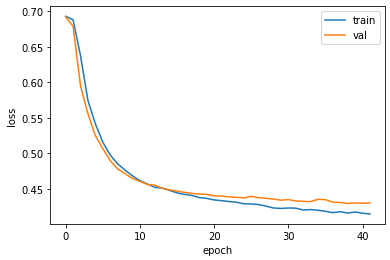
그래프를 보면 과대적합을 제어하면서 손실을 최대한 낮춘 것 같다.
GRU(Gated Recurrent Unit)구조
GRU는 뉴욕 대학교 조경현 교수가 발명한 셀로 유명하다.
LSTM을 간소화한 버전으로 생각할 수 있다.
LSTM 처럼 셀 상태를 계산하지 않고 은닉 상태 하나만 포함하고 있다.
- GRU의 셀
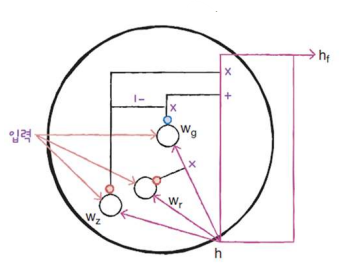
GRU 셀에는 은닉 상태와 입력에 가중치를 곱하고 절편을 더하는 작은 셀이 3개 들어 있다.
2개는 Sigmoid 함수(wr, wz)를 통과하고 한 개는 tanh 함수(wg)를 통과한다.
- wz 셀: 출력이 은닉 상태에 바로 곱해져 삭제 게이트 역할을 수행한다.
- wr 셀: 출력된 값은 wg 셀이 사용할 은닉 상태의 정보를 제어한다.
- wg 셀: 출력을 1 뺀다음 가장 오른쪽 wg를 사용하는 셀의 출력에 곱한다.
GRU 셀은 LSTM보다 가중치가 적기 때문에 계산량이 적지만 LSTM 못지않은 좋은 성능을 낸다.
신경망을 훈련해보자.
- 모델 만들기
model4 = keras.Sequential()
model4.add(keras.layers.Embedding(500, 16, input_length=100))
model4.add(keras.layers.GRU(8))
model4.add(keras.layers.Dense(1, activation='sigmoid'))
model4.summary()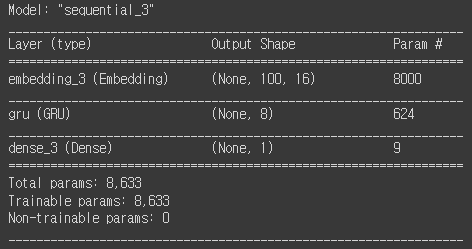
파라미터 개수
- Embedding : 500 x 16 = 8000개
- GRU : (16 x 8 + 8) + (8 x 8 + 8) x 3 = 624
- 입력에 곱하는 가중치 : 16 x 8 = 128개
- 은닉 상태에 곱하는 가중치 : 8 x 8 = 64개
- 절편 : 8개
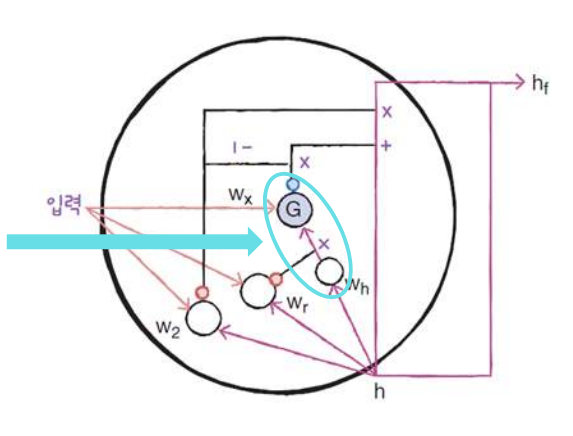
케라스에서는 작은 셀마다 은닉 상태 가중치를 별도의 '더 작은 셀'로 계산후 곱한다.
- 작은 셀의 파라미터 : (16 x 8 + 8) + (8 x 8 + 8) = 208
- Dense : 8 + 1 = 9
- 모델 학습하기
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model4.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-gru-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model4.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
LSTM과 비슷한 성능이 나온다.
- 손실 그래프 그리기
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()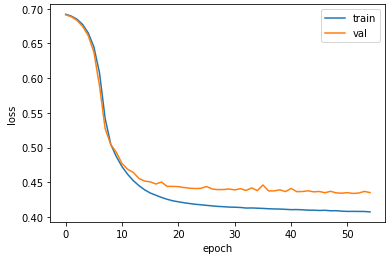
드롭아웃을 사용하지 않았기 때문에 이전보다 훈련 손실과 검증 손실 사이에 차이가 있지만 훈련 과정이 잘 수렴되고 있는 것을 확인할 수 있다.
Pupbani는 이제 LSTM과 GRU를 사용할 수 있게 되었다!
'AI > 딥러닝(Deep Learning)' 카테고리의 다른 글
| [딥러닝/DL] Attention (0) | 2024.01.09 |
|---|---|
| [딥러닝/DL] Loss Surface (0) | 2024.01.09 |
| [딥러닝/DL]8. 순환 신경망으로 IMDB리뷰 분류하기 (1) | 2022.12.08 |
| [딥러닝/DL]7. 순차 데이터와 순환 신경망 (1) | 2022.12.08 |
| [딥러닝/DL]6. 합성곱 신경망의 시각화 (0) | 2022.12.08 |



