Attention을 알기위해서는 seq2seq model에 대해 알아야한다.
seq2seq(Sequence-to-Sequence) Model
한 시퀀스를 다른 시퀀스로 변환 하는 작업을 수행하는 딥러닝 모델로 주로 NLP 분야에서 활용된다.
이 모델은 Encoder와 Decoder라는 모듈을 가지고 있다.
이 두 모듈이 협력하여 입력 시퀀스를 원하는 출력 시퀀스로 변환한다.

Encoder
일반적으로 RNN, LSTM, GRU 등의 순환 신경망 구조를 사용하여 입력 시퀀스를 고정 길이의 벡터로 변환하는 역할을 수행한다.
Encoder는 입력 시퀀스의 단어를 순차적으로 처리하면서 각 단계에서 hidden state를 업데이트하고, 최종적으로 전체 입력 시퀀스를 대표하는 고정 길이의 벡터를 생성한다.
- 임의의 길이의 문장을 고정 길이 벡터로 변환하는 작업
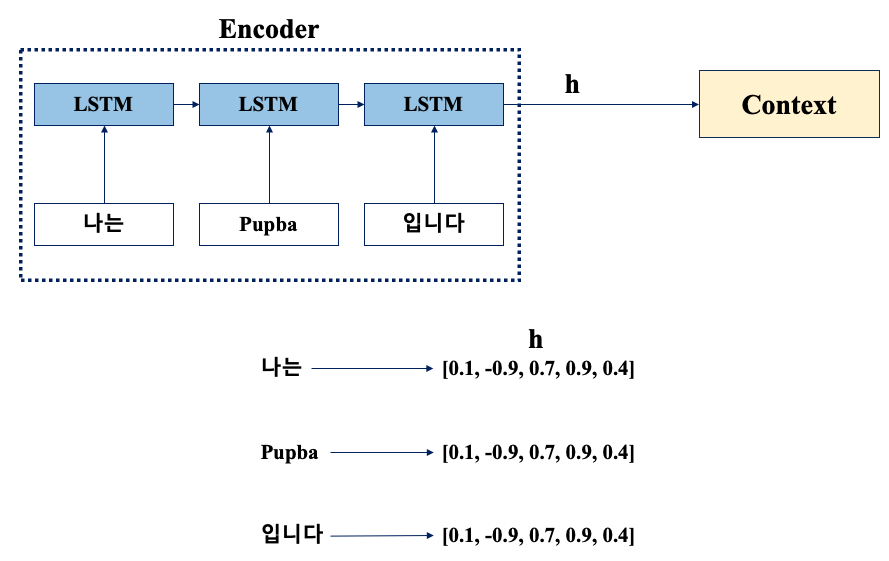
ex. "나는 Pupba 입니다" --Encoder--> 고정 길이 벡터(h)
생성된 벡터는 디코더에 전달한다.
Decoder
Encoder의 출력인 고정 길이의 벡터를 기반으로 원하는 출력 시퀀스를 생성하는 역할을 수행한다.
Decoder 역시 RNN, LSTM, GRU 등의 순환 신경망 구조를 사용한다.
하지만, 입력으로 벡터 h를 받는다는 것이 차이점이다.
일반적으로 Softmax Activation Function를 통해 확률 분포로 변환되어, 가장 높은 확률을 가지는 단어가 선택된다.
이 과정을 반복하여 최종적으로 출력 시퀀스가 생성된다.

Decoder를 살펴보면 <eos>라는 구분 기호가 있는데, 이 기호는 Decoder에 문장 생성과 종료를 알리는 신호로 사용되며 구분 기호는 <go>, <start>, <s>, 등을 이용하기도 한다.
간단한 seq2seq 모델
seq2seq.ipynb
Colaboratory notebook
colab.research.google.com
seq2seq의 한계
인코더가 입력 시퀀스를 하나의 고정된 길이의 벡터로 압축, 이로 인해 입력 시퀀스의 길이가 길어질수록 정보의 손실이 발생할 수 있다.
또 RNN의 고질적인 문제인 경사 소실 또는 폭발 문제가 존재.
이러한 문제들을 극복하기 위해 제안된 방법이 Attention 매커니즘이다.
Attention Mechanism 이란?
seq2seq의 문제들을 극복하기 위해 제안된 방법.
입력 문장의 모든 단어를 동일한 가중치로 취급하지 않고, 출력 문장에서 특정 위치에 대응하는 입력 단어들에 더 많은 가중치를 부여한다.
이를 통해 입력과 출력의 길이가 다른 경우에도 모델이 더욱 정확하고 유연하게 작동할 수 있게된다.
Attention Function
Attention Funtion은 입력 시퀀스의 각 단어들에 대한 가중치를 계산하는 함수
- 각 단어의 중요도를 측정하여 출력 결과에 반영
- Query, Key ,Value로 구성
- Query : 현재 출력 단어를 나타내는 백터
- Key : 입력 시퀀스의 각 단어에 대응하는 벡터
- Value : 입력 시퀀스의 각 단어에 대응하는 벡터
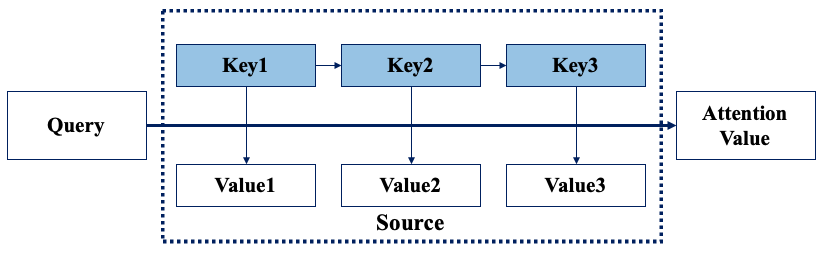
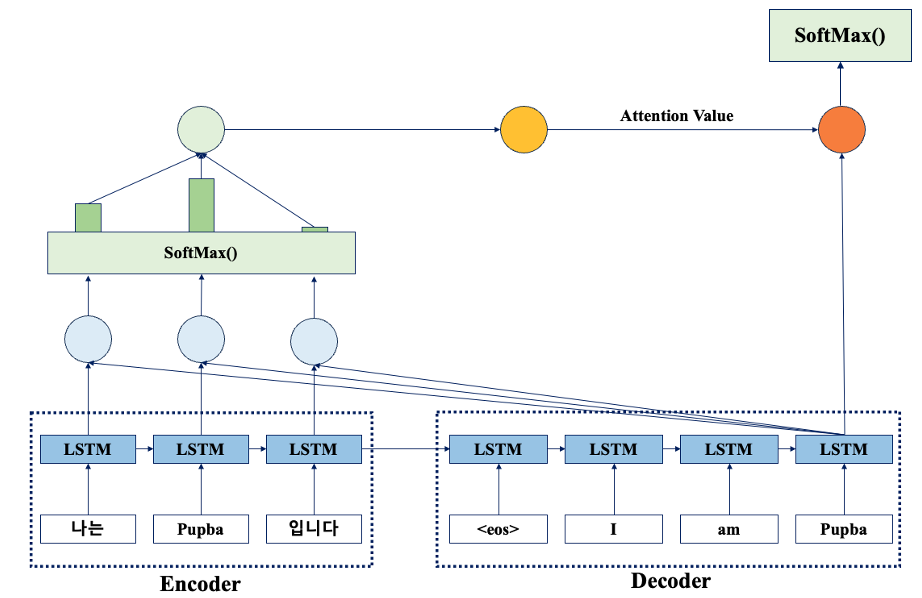
동작 과정
- Query 벡터와 Key 벡터 간의 유사도 측정(내적, 외적 등 다양한 방법으로 계산)
- 유사도를 정규화 하여 각 단어의 가중치를 계산
- 가중치와 Value 벡터와 곱해져 최종 출력 벡터 생성
Attention Function은 주로 Softmax, Sigmoid, ReLU 등과 같은 활성화 함수와 함께 사용된다.
Scaled Dot-Product Attention
Function 계산 수식

key 벡터의 차원 수의 제곱근으로 나누는 이유는 key 벡터의 차원 수가 증가할수록 내적 값이 커지기 때문(다른 토큰들의 가중치가 상대적으로 작아질 수 있음)이다.
V를 곱해 최종 값을 구한다. V를 곱하는 이유는 Attention Weight를 이용하여 입력 시퀀스에서 해당 토큰의 정보를 추출하기 위해서 이다.
동작 과정은 총 3단계로 나뉜다.
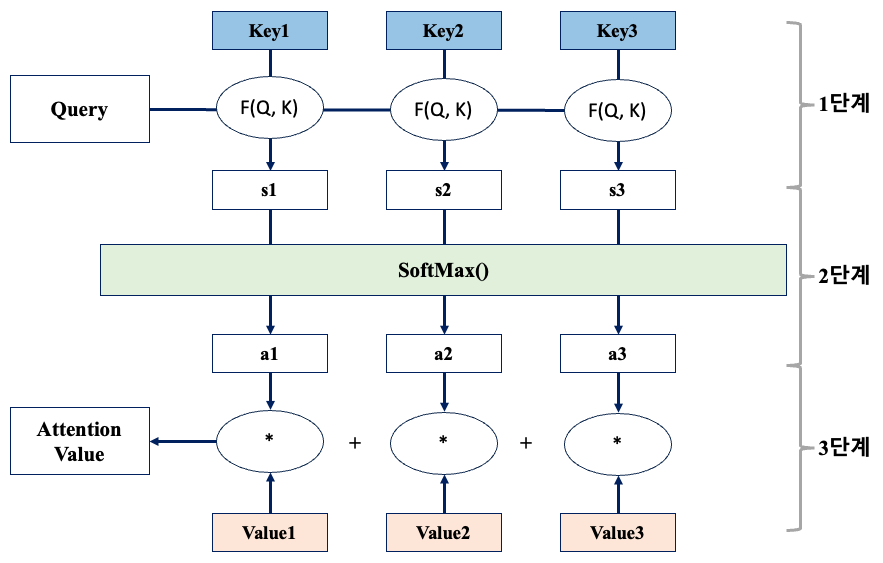
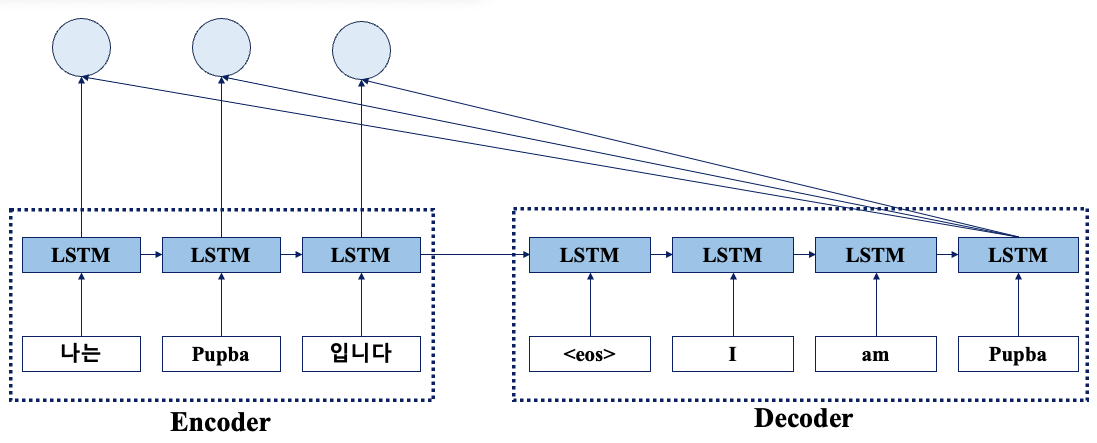
1단계 : Attention Score 계산
Attention Score는 Qurey와 Key 사이의 유사도를 나타내는 값이다.
Query는 Decoder의 t 시점의 은닉 상태, Key는 Encoder의 모든 시점의 은닉 상태를 의미한다.
Query와 Key의 내적을 통해 얻은 값은 유사도를 나타내고, 이 값을 Key 벡터의 차원 수의 제곱근으로 나눠 스케일링한다.
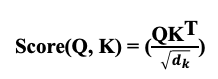
각 인코더 시점의 은닉 상태와 디코더의 t 시점의 은닉 상태간의 Attention Score가 계산된다.
2단계 : Attention Distribution 계산
Attention Score를 SoftMax 함수에 적용하면, 각 인코더 시점의 은닉 상태에 대한 가중치(확률 분포)를 얻을 수 있다.
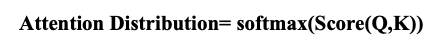
이 가중치는 디코더의 t 시점에 인코더의 각 시점의 정보가 얼마나 중요한지를 나타낸다.
Softmax 함수를 통해 얻은 값은 모든 인코더 시점에 대해 합이 1이되는 확률 분포를 가진다.
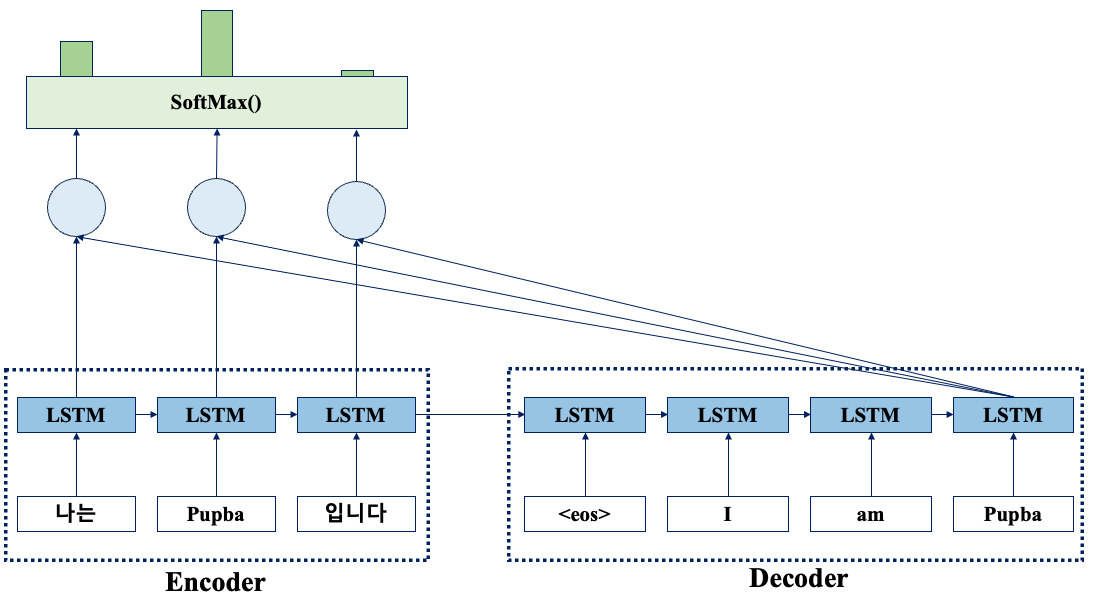
3단계 : Attention Value 계산
Attention Distribution과 Encoder의 값(Value) 벡터를 곱한 후, 모든 인코더 시점에 대해 합산하여 Attention Value를 구한다.

값(Value) 벡터는 Encoder의 각 시점의 은닉 상태를 의미한다.
Attention Value는 Encoder의 정보를 Decoder에 전달하는 역할을 한다.
- Weight를 고려해 각 Encoder 시점의 정보를 조합한 결과물이다.
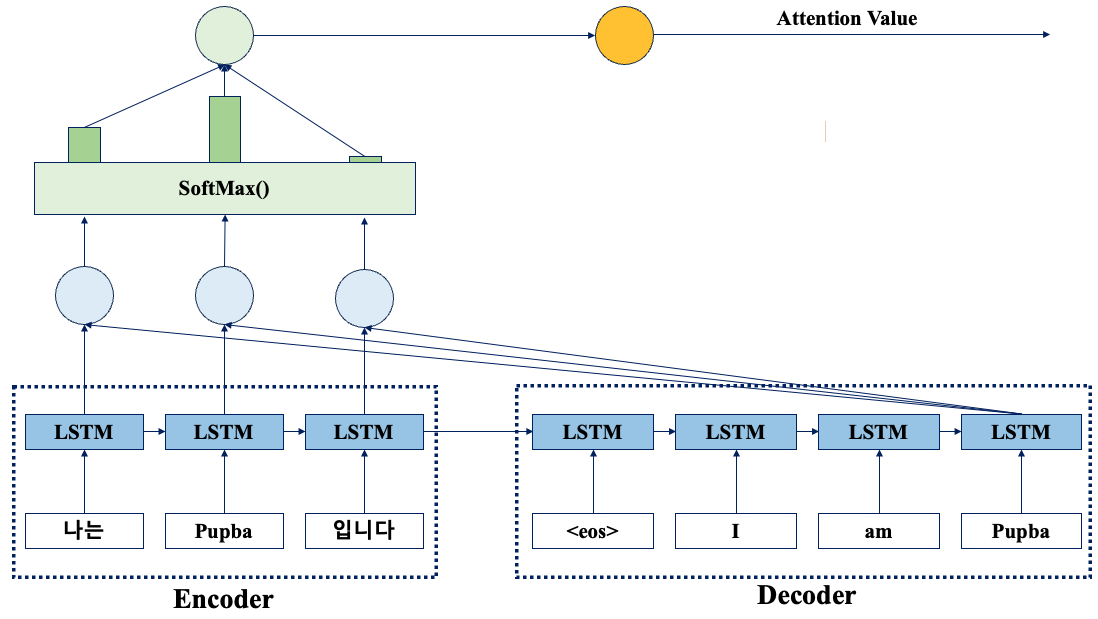
Attention Value와 디코더의 은닉 상태 concatenate
Attention Value와 디코더의 t시점의 은닉상태를 연결하여, 새로운 입력으로 사용한다.
이 메커니즘을 통해 Encoder와 Decoder가 상호 작용하며, 입력 문장의 정보를 공유하게 된다.
(ht : Decoder의 현재 시점의 은닉 상태, ct : Attention 메커니즘의 결과, f : Decoder의 출력을 생성하기 위해 사용되는 활성화 함수)
- 두 벡터를 Concat -> [ht : ct]
- 연결된 벡터를 적절한 크기의 출력 벡터로 변환 -> ot = f([ht : ct])
- 출력 벡터를 Softmax에 적용해서 최종확률 분포를 얻음 -> pt = softmax(ot)
특징
- 계산이 빠르다. (내적 연산은 고속으로 처리할 수 있기 때문에 다른 Attention 방법보다 계산 속도가 빠름)
- 정규화를 위해 스케일링이 사용된다.(스케일링을 통해 가중치의 분산을 조절하여 학습을 안정화, Attention 메커니즘의 성능 향상)
- 병렬 처리가 가능하다.(입력 시퀀스의 각 단어 간의 독립적 계산이 가능하여 더 빠른 학습 속도를 달성할 수 있음)
- 다양한 입력 시퀀스 길이를 처리할 수 있다.(입력 시퀀스의 길이에 대해 제한이 없기 때문에, 다양한 길이의 입력 시퀀스를 처리 가능)
다양한 종류의 어텐션
1. Dot-Product Attention
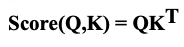
- Q, K의 내적을 사용하여 Attention Score를 계산
2. Scaled Dot-Product Attention
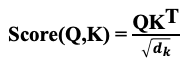
- 내적 값을 Key 벡터의 차원 수의 제곱으로 나누어 스케일링
- 각 차원에 대한 영향력이 과도하게 커지는 것을 방지하고 학습의 안정성을 향상
3. Additive Attention
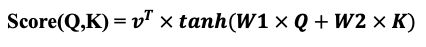
- Qurey와 Key를 결합한 후, 학습 가능한 가중치 행렬을 적용하여 계산하는 방식
- 이후 활성화 함수를 적용한 결과를 가지고 Attention Score를 구함
4. Multi-Head Attention
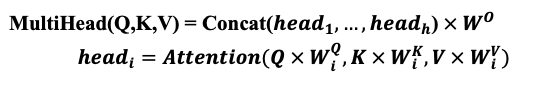
- 여러개의 독립적인 어텐션을 병렬로 수행한 후, 결과를 결합하는 방식
- 각 Attention Head는 서로 다른 Weight를 사용하여 입력에 대한 다양한 관점을 학습할 수 있음
- Scaled Dot-Product Attention을 기반으로 함
'AI > 딥러닝(Deep Learning)' 카테고리의 다른 글
| [딥러닝/DL] Loss Function (0) | 2024.09.09 |
|---|---|
| [딥러닝/DL] Loss Surface (0) | 2024.01.09 |
| [딥러닝/DL]9. LSTM과 GRU 셀 (0) | 2022.12.09 |
| [딥러닝/DL]8. 순환 신경망으로 IMDB리뷰 분류하기 (1) | 2022.12.08 |
| [딥러닝/DL]7. 순차 데이터와 순환 신경망 (1) | 2022.12.08 |



