데이터 모델링과 인덱싱
DB를 사용하는 환경에서 하드웨어 개선없이 성능을 개선하는 방법
데이터 모델링
- 업무 수행 시 발생하는 데이터를 정확하고 효율적으로 DB에 저장하기 위해 데이터 구조를 설계하는 과정
- MongoDB의 특성을 고려하여 저장할 데이터의 구조를 정하는 작업
| DBMS | RDBMS | MongoDB |
| 설계 방식 | 테이블 설계 후 컬럼을 설계함 | 도큐먼트 설계 후 컬렉션을 설계 |
애플리케이션의 처리방안을 고려한 도큐먼트 구조를 어떻게 설계하느냐에 따라 데이터 "정합성(일관성)"과 "성능"에 큰 영향을 주게 되므로 이에 대한 정확한 이해가 필요함.
모델링 예시 - 게시판
- 각 게시판은 "이름"을 가진다.
- 게시판에 글을 쓰는 사용자는 "이름, 생년월일, 포인트"를 가진다.
- 각 게시글은 게시판에 작성 가능, "게시판 id, 사용자 id, 제목, 내용"을 가진다.
- 각 게시글은 "게시글 id, 사용자 id"로 조회한다.
- 각 게시글의 조회 수는 사용자 당 1회만 증가, 동일한 게시글을 여러번 읽어도 추가로 증가하지 않는다.
| 게시판 컬렉션과 컬렉션 | ||||
| 컬렉션 | 사용자 | 게시판 | 게시글 | 조회 |
| 필드 | 이름 생년월일 포인트 |
이름 | 게시판 id 사용자 id 제목 내용 |
게시글 id 사용자 id |
- 게시판에 존재하는 관계 대응수
- 게시판과 게시글 = 1:N
- 사용자와 게시글의 조회 = N:M
- 사용자와 포인트 = 1:1
- MongoDB에서도 도큐먼트들 사이에 존재하는 관계(외래키)를 표현하는 방법이 필요함.
관계를 표현하기 위한 도큐먼트 구조
embedded 방식
- 다른 객체를 도큐먼트 내부에 포함 시키는 방식
- 장점
- 원자성을 지키기 쉬움
- 내용을 읽는 시간이 빠름
- 도큐먼트가 여러 서버에 나뉘어져(샤딩) 있을 때 속도 차이가 커짐
- 빈번하게 함께 읽게 되는 정보는 임베디드 방식을 사용하는 것이 좋음
- 단점
- 도큐먼트 사이즈 제한(16MB)이 있어 문제가 생김
- 도큐먼트 사이즈가 크면 램에 불러들여 수정할 때 속도가 느려짐
- 도큐먼트 사이즈는 100KB 이하로 유지하는 것을 추천
- 데이터의 중복으로 인한 저장 공간이 많이 필요
예시1 - 1:N의 경우
db.modeling.insertOne({
_id : "Pupbani",
name : "Pupbani J",
tel : [
{kind : "main",tel_num : "010-1234-1234"},
{kind : "sub1",tel_num : "010-1111-2121"},
{kind : "sub2",tel_num : "010-2234-1234"},
]
})
예시2 - 도서 출판사 정보 저장
db.modeling.insertMany([
{
title : "Pupbani와 함께 몽고디비 배우기",
author : ["Pupbani","Jake"],
published_date : ISODate("2022-10-12"),
pages : 250,
language : "한글",
publisher : {
name : "IT 출판사",
founded : 1990,
location : "CA"
}
},
{
title : "Pupbani와 함께 DB 배우기",
author : ["Pupbani","Jony"],
published_date : ISODate("2022-12-12"),
pages : 252,
language : "영어",
publisher : {
name : "IT 출판사",
founded : 1990,
location : "CA"
}
}
])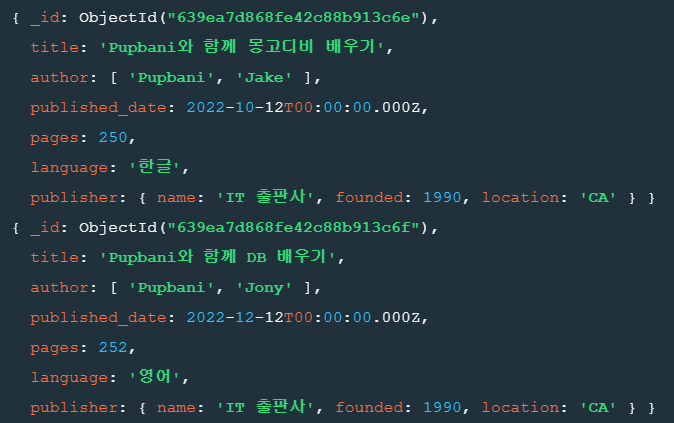
동일한 출판사에 대하여, 정보는 계속 중복됨
reference 방식
- 참조할 도큐먼트의 id를 저장하는 방식
예시 - 도서와 출판사
db.modeling.insertMany([
{
name : "IT 출판사",
founded : 1990,
location : "CA",
books : [4106,8211]
},
{
_id : 4106,
title : "Pupbani와 함께 몽고디비 배우기",
author : ["Pupbani","Jake"],
published_date : ISODate("2022-10-12"),
pages : 250,
language : "한글",
},
{
_id : 8211,
title : "Pupbani와 함께 DB 배우기",
author : ["Pupbani","Jony"],
published_date : ISODate("2022-12-12"),
pages : 252,
language : "영어",
}
])
출판사와 도서 정보를 분리하고 출판사에서 만들어진 도서는 배열에 저장.
도서의 _id를 사용하여 1:N의 관계를 표현.
| (임베디드)내장 방식이 좋은 경우 | (레퍼런스)참조 방식이 좋은 경우 |
| 작은 서브 도큐먼트 | 큰 서브 도큐먼트 |
| 주기적으로 변하지 않는 데이터 | 자주 변하는 데이터 |
| 결과적인 일관성이 허용될 때 | 즉각적인 일관성이 필요할 때 |
| 증가량이 적은 도큐먼트 | 증가량이 많은 데이터 |
| 빠른 읽기 | 빠른 쓰기 |
애플리케이션 설계시 고려사항
- 스키마 설계
- 데이터 내장 방식과 참조 방식의 선택
- 최적화 팁
- 일관성 고려 사항
- 스키마 마이그레이션
- 스키마 관리 방
스키마 설계
데이터 표현의 핵심 요소 - 데이터가 도큐먼트에서 표현되는 방식인 "스키마의 설계"
애플리케이션에서 원하는 방식으로 데이터를 표현하는 것이 좋음
스키마 모델링 전에 쿼리, 데이터 접근 패턴을 이해해야함.
스키마 설계 시 고려사항
- 제약사항
- DB와 H/W 사이의 제약 사항의 이해 필요
- MongoDB 도큐먼트의 최대 크기는 16MB
- 갱신은 전체 도큐먼트를 다시 쓰며, 원자성 갱신은 도큐먼트 단위로 실행
- 쿼리 및 쓰기의 접근 패턴
- 쿼리가 실행되는 시기와 빈도 파악
- 쿼리를 식별한 후에 쿼리 수를 최소화, 함께 쿼리되는 데이터가 동일한 도큐먼트에 저장되도록 설계
- 관계 유형
- 애플리케이션 요구 사항 측면과 도큐먼트 간 관계 측면에서 어떤 데이터가 관련되어 있는지 파악
- 그런 다음 도큐먼트를 내장하거나 참조할 방법 결정
- 카디널리티
- 1:1, 1:N, N:M의 대응수를 고려
- 해당 데이터를 읽기 갱신 비율도 생각해야함.
스키마 설계 패턴
- 다형성 패턴
- 컬렉션 내의 도큐먼트가 유사하지만 동일하지 않은 구조를 가질 때, 공통 필드를 식별하는 것이 필요함
- 속성 패턴
- 쿼리하려는 도큐먼트에 필드의 서브셋이 있는 경우, 쿼리하려는 필드가 도큐먼트 서브셋에만 있는 경우
- 배열로 만들고 배열에 인덱스를 만듬
- 버킷 패턴
- 데이터가 일정 기간 동안 스트림으로 유입되는 시계열 데이터에 적합함
- 특정 시간 범위의 데이터를 버킷화하여 효율적임
- 이상치 패턴
- 도큐먼트의 쿼리가 애플리케이션의 정상적인 패턴을 벗어날 때 사용
- 도서나 영화의 인기도가 갑자기 올라가면 플래그를 설정하고 추가적인 도큐먼트 만듬
- 계산된 패턴
- 데이터를 자주 계산해야 할 때는 데이터 접근 패턴이 읽기 집약적일 때
- 백그라운드에서 계산을 수행하고, 계산값에 대한 근사치를 제공
- 서브셋 패턴
- 장비의 램 용량을 초과하는 작업이 있을 때 사용
- 자주 사용하는 데이터와 자주 사용하지 않는 데이터를 다른 컬렉션으로 분할
- 확장된 참조 패턴
- 전자 상거래에서 주문시 자주 이용되는 필드는 고객의 이름과 주소
- 데이터를 중복 시키지 않고 정보를 조합하여 쿼리를 만듬
- 근사 패턴
- 정확도가 반드시 필요하지 않은 상황에서 유리
- 게시글의 카운트를 한 번 마다 갱신하지 않고 10번이나 100번마다 갱신 할 수 있음
- 트리 패턴
- 쿼리가 많고 구조적으로 계층적인 데이터가 있을 때 사용
- "하드 드라이브"는 "기억장치"와 "전자장치" 카테고리에 속하고, 어느 쪽에서도 찾을 수 있어야 함
정규화 vs 비정규화
- 정규화
- 컬렉션간의 참조를 이용해 데이터를 여러 컬렉션으로 나누는(분해) 작업
- 비정규화
- 모든 데이터를 하나의 도큐먼트에 내장하는 것
- 정규화와 비정규화를 결정하는 것은 쉬운 일이 아님
- 정규화는 쓰기를 빠르게 만들고, 비정규화는 읽기를 빠르게 만듬
카디널리티
하나의 컬렉션이 다른 컬렉션을 얼마나 참조하는지 나타내는 개념
- 1:1, 1:N, N:M
MongoDB를 사용할 때는 "다수"라는 개념을 "많음"과 "적음"이라는 하위 범위로 나누면 개념상 도움이 됨.
- 일대소 관계 - 각 사용자가 게시물을 조금만 작성할 경우 게시자와 게시글의 관계
- 다대소 관계 - 태그보다 게시물이 더 많을 경우 게시물과 태그의 관계
많고 적음을 결정하면 무엇을 내장하고 무엇을 참조할지 결정하는데 도움이 됨.
- "적음"관계는 내장이 더 적합하고, "많음"관계는 참조가 더 적합함.
데이터 조작을 위한 최적화
애플리케이션 최적화를 하려면 읽가와 쓰기 성능을 분석해 어느쪽에서 병목 현상이 일어나는지 파악 필요
읽기 최적화
- 일반적으로 올바른 인덱스를 사용해 하나의 도큐먼트에서 가능한 한 많은 정보를 반환하는 것과 관련 있음.
쓰기 최적화
- 보통 갖고 있는 인덱스 개수를 최소화, 갱신을 가능한 효율적으로 수행하는 것과 관련 있음.
빠른 읽기와 쓰기에 최적화된 스키마는 종종 trade-off가 발생 , 애플리케이션에서 어떤 것이 더 중요한지 결정해야 함.
어떤 애플리케이션에서 쓰기가 더 중요하지만 각 쓰기에 대해 읽기를 수천번 한다면 읽기를 먼저 최적화해야함.
오래된 데이터 제거
어떤 데이터는 짧은 시간 동안만 중요
오래된 데이터를 제거하는 3가지 방법
- capped collection
// capped 컬렉션 생성
db.createCollection("cap_Col",{capped:true,size:100000})
// 컬렉션이 capped 컬렉션인지 확인
db.cap_Col.isCapped()
- TTL(Time-To-Live) collection
// 지정시간 후에 삭제
db.ttl_Col.createIndex({"lastModifiedDate":1},{expireAfterSeconds:50})
// 도큐먼트 삽입
db.ttl_Col.insert({"test":"hello","lastModifiedDate":new Date()})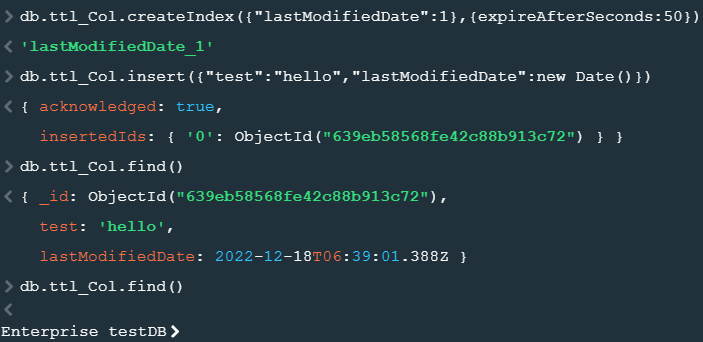
- 주기적으로 컬렉션 삭제
db.ttl_Col.drop()
데이터베이스와 컬렉션 구상
- 도큐먼트 형태에 대한 구상이 끝나면 어떤 컬렉션 또는 어떤 DB에 넣을지 결정해야 함.
- 지침 - 스키마가 유사한 도큐먼트는 같은 컬렉션에 보관함
- 컬렉션에서는 lock과 저장을 중요하게 고려해야 함
- DB내 모든 항목이 비슷한 품질, 비슷한 접근 패턴, 비슷한 트래픽 수준을 갖는 것이 좋음
- MongoDB 4.2 이전에는 DB를 여러 개 사용하면 몇 가지 제약이 있음
- $merge 연산자를 통해 결과를 다른 DB나 다른 collection에 저장할 수 있음.
일관성 관리
애플리케이션의 "읽기"에 필요한 일관성이 어느 정도인지 파악해야 함.
MongoDB는 다양한 수준의 일관성을 제공함
실시간 거래를 수행하기 위해 최근 쓴 데이터에 즉각적으로 읽기를 수행할 필요 있음
readConcern
- 읽을 데이터의 일관성과 격리 속성을 제어
- 제공하는 수준(level)
- local
- 과반수에 기록되었음을 확인하지 않고 데이터 반환(읽어온 데이터가 롤백될 수 있음)
- causally consistent session 또는 트랜잭션에서 사용
- available
- 과반수에 기록되었음을 확인하지 않고 반환(읽어온 데이터가 롤백될 수 있음)
- causally consistent session 또는 트랜잭션에서 사용할 수 없음
- 샤딩된 클러스터에서 가장 낮은 레이턴시를 제공
- 샤드된 컬렉션에서 orphaned document를 반환할 수 있음
- majority
- 과반수에 기록된 데이터를 반환
- 이를 충족하기 위해 각 레플리카 셋 멤버들이 메모리의 majority-commit point 반환해야 함 이로 인해 위의 두 설정에 비해 성능이 떨어짐.
- causally consistent session 또는 트랜잭션에서 사용
- PSA 아키텍처를 사용할 때 이 설정을 쓰지 않게 설정 가능(Change Streams, 트랜잭션, 샤디드 클러스터에 영향을 줄 수 있음)
- linearizabe
- 읽기를 시작하기 전에 완료된 쓰기에 대한 데이터만 반환함.
- 쿼리가 결과를 반환하기 전에 레플리카 셋 전체에 결과가 전파되길 기다림.
- 읽기 시작 후 레플리카 셋의 과반이 재시작되어도, 반환된 데이터는 유효(writeConcernMajorityJournalDefault을 false로 변경하면 아닐 수 있음)
- causally consistent session 또는 트랜잭션에서 사용할 수 없음
- 프라이머리 노드에만 설정할 수 있음
- aggregate의 $out, $merge 스테이지에서 사용할 수 없음
- 유니크하게 식별가능한 단일 도큐먼트에 읽기 작업에서만 보장
- snapshot
- 트랜잭션이 causally consistent session이 아니고 writeConcern이 majority인 경우, 트랜잭션은 과반이 커밋된 데이터의 스냅샷에서 읽음
- 트랜잭션이 causally consistent session이고 writeConcern이 majority인 경우, 트랜잭션 시작 직전에 과반이 커밋된 데이터의 스냅샷에서 읽음
- 멀티 도큐먼트 트랜잭션에서만 사용가능
- 샤딩된 클러스터 중 하나라도 Disable Read Concern Majority 설정을 할 경우 사용할 수 없
- local
writeConcern
- readConcern와 결합하여 애플리케이션에 대한 일관성과 가용성을 제어할 수 있음.
- 제공 수준(w)
- majority
- number - 0 or 1
- custom write concern name
스키마 마이그레이션(migration)
- 애플리케이션의 규모가 커지고 요구사항이 변할수록 스키마도 커지고 변환해야 함
- 스키마 애플리케이션의 요구에 맞춰 변화시키는 방법
- version 필드를 사용하는 방법
- 스키마가 변경될 때 모든 데이터를 마이그레이션하는 방법
'DB > MongoDB' 카테고리의 다른 글
| [MongoDB] 19. 파이썬과 MongoDB 연동 (0) | 2022.12.18 |
|---|---|
| [MongoDB] 18. 데이터 모델링과 인덱스 - 인덱스 (0) | 2022.12.18 |
| [MongoDB] 16. 집계명령어 - 트랜잭션 (0) | 2022.12.18 |
| [MongoDB] 15. 집계명령어 - 다양한 연산자, 뷰 (0) | 2022.12.17 |
| [MongoDB] 14. 집계명령어 - 고급 스테이지, 여러가지 스테이지 (0) | 2022.12.17 |



