🥑 Coursera의 "Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and
Optimization" 강좌의 내용을 배우면서 개인적으로 정리한 내용입니다.
Hyperparameter Tuning
하이퍼파라미터는 파라미터와 구분하여 사용자가 딥러닝을 위해 설정하는 값들을 모두 지칭한다.
하이퍼파라미터는 다양하게 존재하지만 중요성은 다르다고 할 수 있다.
- Adam의 B1, B2, e은 거의 변경하지 않고 기본값을 사용한다.(거의 중요하지 않음...)
- hidden units, mini-batch size 등은 데이터 크기와 종류에 따라 설정해야한다.(중요!)
이런 하이퍼파라미터 값은 튜닝하려고 할 때, 하이퍼파라미터는 어떻게 설정해서 탐색 해야할까?

머신러닝 알고리즘 개발 초기에, 2개의 하이퍼파라미터가 있는 경우 5x5 grid로 설정하고 25개의 point 중 잘 동작하는 것으로 골랐다.
하지만 이 방법은 하이퍼파라미터의 개수가 비교적 많지 않은 경우에 잘 동작하는 편이다.
딥러닝의 경우에 추천하는 방법은 각 point의 위치를 임의로 선택하는 방법이다.
이 방법을 사용하는 이유는, 어떤 하이퍼파라미터가 해결하려는 문제에서 가장 중요한지 미리 알 수 없기 때문이다.
첫번째 방법대로 샘플링을 진행한 경우 25개의 모델을 학습하나 5개의 하이퍼파라미터 값(25개의 모델 학습)으로 시도할 수 있다.
두번째 방법대로 샘플링 무작위로 진행한다면, 각각 모델마다 25개의 하이퍼파라미터 값(625개의 모델 학습)을 시도하게 된다.
하이퍼파라미터 샘플링의 경우 Coarse to find searching 방법이 자주 사용된다.
Coarse to find searching
- 초기에는 넓은 범위에서 탐색을 시작하여 점차적으로 세부 범위로 좁혀가며 효율적인 탐색을 수행하는 방법이다.
다음과 같은 절차로 수행된다.
1. Coarse Search(넓은 범위 탐색)
- 초기에는 넓은 하이퍼파라미터 범위를 정의한다.
- 이 범위에서 몇 개의 샘플 하이퍼파라미터 조합을 선택하여 모델을 학습하고 검증한다.
- 이 과정은 초기 탐색 단계이므로 세밀한 조정보다는 대략적인 트렌드 파악에 초점을 둔다.
2. Fine Search(세부 범위 탐색)
- Coarse Search를 통해 얻은 결과를 분석하고, 성능이 우수한 하이퍼파라미터 조합을 선정한다.
- 이 선택된 조합 주변의 좁은 범위에서 추가적인 탐색을 진행한다.
- 이 단계에서는 더 세부적인 하이퍼파라미터 값을 탐색하여 최적의 조합을 찾는다.
임의의 샘플링을 진행하고, 충분히 탐색한 후에 선택적으로 사용하면 된다.
범위가 다른 하이퍼파라미터에서 효율적으로 탐색
단순히 임의로 하이퍼파라미터를 샘플링하는 것은 특정한 유효한 범위에서 탐색하는 것이 아니기 때문에 비효율적일 수 있다.
때문에 적합한 scale을 선택해서 탐색하는 것이 중요하다.
예시1 :
hidden unit의 개수가 n[l]의 값을 탐색한다고 가정, 잘 동작하는 범위가 50 ~ 100일 때
hidden unit의 개수가 50 ~ 100 사이의 값으로 선택하는 것이 비교적 합리적인 방법이라고 할 수 있다.
예시2 :
NN의 layer 개수를 결정하려고 하면, 2 ~ 4개가 잘 동작한다고 생각할 때 2,3,4 사이에서 선택하는 것이 합리적이다.
예시3:
learning rate alpha를 탐색할 때, 0.0001 ~ 1 값 사이로 임의로 균일화되게 샘플링을 진행하면, 약 90% 값이 0.1 ~ 1 사이에 있을 것이다. 이 방법은 샘플링의 90% 정도를 0.1 ~ 1 값에 집중, 10% 정도만이 0.0001과 0.1 사이의 값에 집중하기 때문에 log scale을 적용해서 탐색하는 것이 더 적합할 것이다.
한 분야에서 사용되는 적절한 하이퍼파라미터가 다른 분야에 적용(Cross-fertilization)이 될 수 있다.
Ex. Confonets or ResNets -> NLP
하이퍼파라미터는 시간이 지나면 데이터가 변하거나 하기 때문에 더 이상 최적의 파라미터가 아니게 될 수 있다.
그러므로 re-evaluate하는 추천한다.
탐색 방법에는 2가지가 있다.
1. Babysitting one model
- 하나의 모델을 학습하는 동안 집중적으로 관찰하고 조정하는 것을 의미한다.
- 데이터가 아주 많거나, 연산을 위한 Resource가 많이 없을 때(GPU등..가 충분하지 않고 한번에 1가지 모델만 학습할 수 있을 경우)
- 모델 학습 도중 발생할 수 있는 문제를 신속하게 감지하고 해결하기 위해 모델을 지속적으로 모니터링하며, 하이퍼파라미터 조정이나 학습 과정 수정을 수행한다.
- 세밀한 조정을 통해 최상의 결과를 얻을 수 있지만, 시간과 인력이 많이 소요될 수 있다.
2. Training many models in parallel
- 여러 개의 모델을 동시에 병렬로 학습하는 것을 의미한다.
- 어느 한 모델에 대해서 하이퍼파라미터의 값을 설정해서 학습할 수 있고, 여러 모델에 대한 Learning curve를 얻을 수 있다.
- 모델의 수가 많을수록 계산 비용이 증가하고 자원소모가 크기 때문에 충분한 컴퓨팅 자원이 필요하다.
Batch Normalization
Batch Normalization은 하이퍼파라미터 탐색을 더 쉽게 만들어 준다.
앞에서 포스팅 Normalization 내용에 대해 살펴보면 Normalization은 input의 평균과 분산을 조절해 더 동그랗게 cost를 변형해서 GD의 속도를 높혀준다.
deep model의 경우 입력이 X만 있는게 아니라 a[1],[2](모델의 레이어 간의 출력), 활성화 함수를 통과한 결과 등이 있다. 이 경우 Batch Normalization 알고리즘을 적용한다.
적용하는 과정은 다음과 같다.
1. Mini-batch 단위로 정규화
- 입력 데이터를 Mini-batch 단위로 나누어 정규화를 수행
2. 평균과 분산 계산
- Mini-batch 내의 각 feature map의 평균과 분산을 계산
- 이를 통해 Mini-batch 내의 데이터 분포를 파악할 수 있음
3. 정규화
- 평균과 분산을 사용하여 Mini-batch 내의 데이터를 정규화
- 각 feature map의 값들을 평균을 빼고, 분산으로 나누어 정규화
- 이를 통해 데이터의 분포를 평균이 0이고 분산이 1인 분포로 조정
4. 스케일 조정과 이동
- 정규화된 데이터에 대해 scale 조정과 shift를 수행
- 스케일 조정 파라미터와 이동 파라미터를 사용하여 데이터의 분포를 조정
- 이를 통해 모델이 최적의 분포로 학습할 수 있게 도움을 줌
5. 활성화 함수 적용
- 정규화된 데이터에 활성화 함수를 적용
- 활성화 함수는 비선형성을 추가하여 모델이 다양한 패턴을 학습할 수 있도록 도와줌
Deep learning Framework를 사용하는 경우 직접 구현할 필요 없이, tf.nn.batch_normalization을 사용하면된다.
Batch Normalization이 왜 잘 동작하는 이유
- input feature를 normalization 하여 평균 0, 분산을 1로 만들어 학습의 속도를 증가
- 모든 특성을 normalization 하기 때문에. input feature x가 비슷한 범위를 갖게 됨
- batch normalization을 통해 모델이 weight의 변화에 덜 민감해짐
Batch Norm의 공식
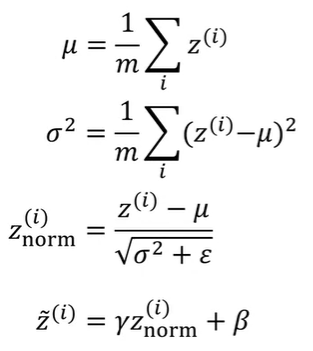
Batch Normalization.ipynb
Colaboratory notebook
colab.research.google.com
'AI > Coursera' 카테고리의 다른 글
| [Coursera] 8. Softmax (0) | 2024.01.01 |
|---|---|
| [Coursera] 6. Opitmization (0) | 2023.12.31 |
| [Coursera] 5. Optimization Problem (0) | 2023.12.28 |
| [Coursera] 4. Practical Aspects of Deep Learning (0) | 2023.12.27 |
| [Coursera] 3. Gradient Descent (0) | 2023.12.27 |



